Drop duplicate rows in pandas python drop_duplicates()
In this section we will learn how to delete or drop duplicate rows of a dataframe in python pandas with example using drop_duplicates() function. lets learn how to
Delete or Drop duplicate rows in pandas python using drop_duplicate() function
Drop the duplicate rows in pandas by retaining last occurrence
Delete or Drop duplicate in pandas by a specific column name
subset: Subset takes a column or list of column label for identifying duplicate rows. By default, all the columns are used to find the duplicate rows.
keep: allowed values are {‘first’, ‘last’, False}, default ‘first’. If ‘first’, duplicate rows except the first one is deleted. If ‘last’, duplicate rows except the last one is deleted. If False, all the duplicate rows are deleted.
inplace: if True, the source DataFrame itself is changed. By default, source DataFrame remains unchanged and a new DataFrame instance is returned.
Create dataframe:
import pandas as pd
import numpy as np
#Create a DataFrame
import pandas as pd
import numpy as np
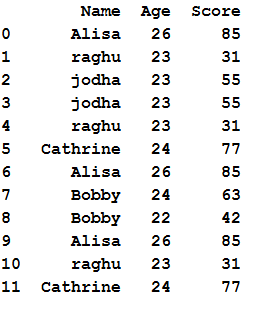
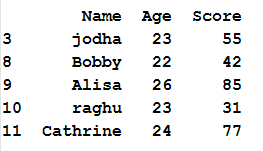
d = { 'Name':['Alisa','raghu','jodha','jodha','raghu','Cathrine', 'Alisa','Bobby','Bobby','Alisa','raghu','Cathrine'],
'Age':[26,23,23,23,23,24,26,24,22,26,23,24],
'Score':[85,31,55,55,31,77,85,63,42,85,31,np.nan]}
df = pd.DataFrame(d,columns=['Name','Age','Score'])
df
so the resultant dataframe will be
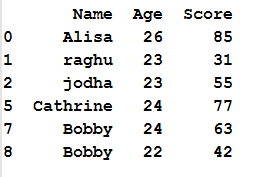
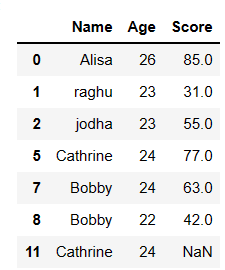
1. Drop the duplicate rows in pandas: by default it keeps the first occurrence of duplicate
Now lets simply drop the duplicate rows in pandas using drop_duplicates() function as shown below
# drop duplicate rows
df.drop_duplicates()
In the above example first occurrence of the duplicate row is kept and subsequent occurrence will be deleted, so the output will be
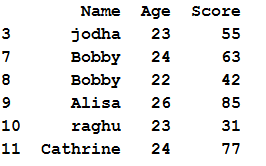
2. Drop duplicate rows by retaining last occurrence in pandas python:
# drop duplicate rows
df.drop_duplicates(keep='last')
In the above example keep=’last’ argument . Keeps the last duplicate row and delete the rest duplicated rows. So the output will be
3. Delete All Duplicate Rows from DataFrame in pandas
#### Drop all duplicates
result_df = df.drop_duplicates(keep=False)
result_df
In the above example keep=False argument . Keeps only the non duplicated rows. So the output will be
4. Drop the duplicates by a specific column in pandas: Method 1
Now let’s drop duplicate by column name. Rows are dropped in such a way that unique column value is retained for that column as shown below
# drop duplicate by a column name
df.drop_duplicates(['Name'], keep='last')
In the above example rows are deleted in such a way that, Name column contains only unique values
So the result will be
4. Drop the duplicates by a specific columns: Method 2
Now let’s drop duplicates by multiple column names. Rows are dropped in such a way that unique column value is retained for those mentioned columns as shown below
# drop duplicate by multiple column name
df.drop_duplicates(subset=['Age', 'Score'])
In the above example duplicate rows are dropped based on Age and Score Column, combination of these two column has unique vlaues
So the result will be
5. Drop duplicate rows in pandas python by inplace = “True”
Now lets simply drop the duplicate rows in pandas source table itself as shown below
# drop duplicate rows
df.drop_duplicates(inplace=True)
In the above example first occurrence of the duplicate row is kept and subsequent occurrence will be deleted and inplace = True replaces the source table itself, so the output will be
With close to 10 years on Experience in data science and machine learning Have extensively worked on programming languages like R, Python (Pandas), SAS, Pyspark.

 of a dataframe in python Pandas")




