Cumulative sum of the column in R can be accomplished by using cumsum function. We can also calculate the cumulative sum of the column with the help of dplyr package in R. Cumulative sum of the column by group (within group) can also computed with group_by() function along with cumsum() function along with conditional cumulative sum which handles NA. In this section we will see how to
- Get cumulative sum of column in R
- Get cumulative sum of the column by group (within group) using group_by() and cumsum() function
- Get Cumulative sum of the column with dplyr package.
- Reverse cumulative sum of column
- Cumulative sum based on a condition i.e. conditional cumulative sum in R – cumsum() handling NA
Let’s first create the dataframe
my_basket = data.frame(ITEM_GROUP = c("Fruit","Fruit","Fruit","Fruit","Fruit","Vegetable","Vegetable","Vegetable","Vegetable","Dairy","Dairy","Dairy","Dairy","Dairy"),
ITEM_NAME = c("Apple","Banana","Orange","Mango","Papaya","Carrot","Potato","Brinjal","Raddish","Milk","Curd","Cheese","Milk","Paneer"),
Price = c(100,80,80,90,65,70,60,70,25,60,40,35,50,120))
my_basket
dataframe my_basket will be

Get cumulative sum of column in R:
Cumulative sum of a column is calculated using cumsum() function. cumsum() function takes column name as argument and calculates the cumulative sum of that argument as shown below
# cumulative sum my_basket$cumulative_price = cumsum(my_basket$Price) my_basket
resultant dataframe will be

Cumulative sum of the column in dplyr package :
Cumulative sum of a column is calculated using cumsum() function. cumsum() function along with dplyr pipe operator (%>%) takes column name as argument and calculates the cumulative sum of that argument as shown below
### Cumulative sum of the column by dplyr package library(dplyr) my_basket %>% mutate(cumulative_price = cumsum(Price))
so the cumulative sum of the price column is calculated as shown below
Cumulative sum of the column by group (within group) in dplyr package:
Cumulative sum of a column by group is calculated using cumsum() function and group_by() function of the dplyr package. cumsum() function takes column name as argument and calculates the cumulative sum of that argument. group_by() function takes the column to be grouped as shown below
### Cumulative sum of the column by group using dplyr package library(dplyr) my_basket %>% group_by(ITEM_GROUP) %>% mutate(cum_price_by_item_grp = cumsum(Price))
so the cumulative sum of the “Price” column by “ITEM_GROUP” is calculated as shown below

Get Reverse cumulative sum of column:
Reverse cumulative sum of a column is calculated using rev() and cumsum() function. cumsum() function takes up column name as argument which computes the cumulative sum of the column and it is passed to rev() function which reverses the cumulative sum as shown below.
# reverse cumulative sum my_basket$rev_cumulative_price = rev(cumsum(my_basket$Price)) my_basket
resultant dataframe with reverse cumulative sum calculated will be

Conditional Cumulative sum – cumsum() with NA handling in R:
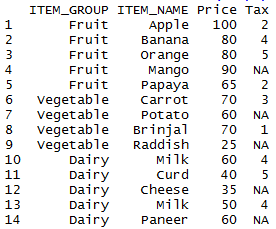
Let’s first create the dataframe
my_basket = data.frame(ITEM_GROUP = c("Fruit","Fruit","Fruit","Fruit","Fruit","Vegetable","Vegetable","Vegetable","Vegetable","Dairy","Dairy","Dairy","Dairy","Dairy"),
ITEM_NAME = c("Apple","Banana","Orange","Mango","Papaya","Carrot","Potato","Brinjal","Raddish","Milk","Curd","Cheese","Milk","Paneer"),
Price = c(100,80,80,90,65,70,60,70,25,60,40,35,50,60),
Tax = c(2,4,5,NA,2,3,NA,1,NA,4,5,NA,4,NA))
my_basket
dataframe my_basket will be
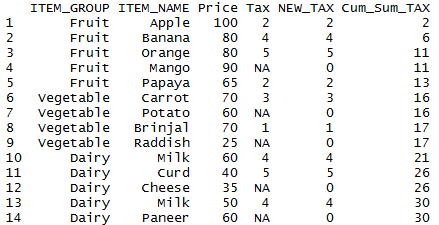
Handling NA on cumulative sum:
In our example we have used mutate function to create new variable and NA’s are replaced with 0 and cumulative sum of the Tax column is calculated.
### cumulative sum and handling NA values
my_basket %>% mutate( NEW_TAX = ifelse( is.na(Tax), 0, Tax ), #remove NA
Cum_Sum_TAX = cumsum(NEW_TAX) )
so the resultant dataframe with cumulative sum of the Tax column calculated by replacing NA’s with 0
for further understanding of cumulative sum of the column using dplyr in R one can refer documentation.
Other Related Topics:
![]()
![]()





