Repeat or replicate the rows of dataframe in pandas python (create duplicate rows) can be done in a roundabout way by using concat() function. Let’s see how to
- Repeat or replicate the dataframe in pandas python.
- Repeat or replicate the dataframe in pandas along with index.
With examples
First let’s create a dataframe
import pandas as pd
import numpy as np
#Create a DataFrame
df1 = {
'State':['Arizona AZ','Georgia GG','Newyork NY','Indiana IN','Florida FL'],
'Score':[62,47,55,74,31]}
df1 = pd.DataFrame(df1,columns=['State','Score'])
print(df1)
df1 will be
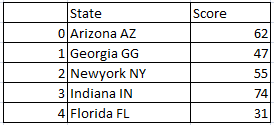
Repeat or replicate the rows of dataframe in pandas python:
Repeat the dataframe 3 times with concat function. Ignore_index=True does not repeat the index. So new index will be created for the repeated columns
''' Repeat without index ''' df_repeated = pd.concat([df1]*3, ignore_index=True) print(df_repeated)
So the resultant dataframe will be
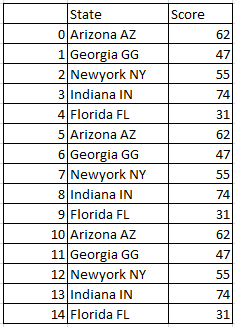
Repeat or replicate the dataframe in pandas with index:
Concat function repeats the dataframe in pandas with index. So index will also be repeated
''' Repeat with index''' df_repeated_with_index = pd.concat([df1]*2) print(df_repeated_with_index)
So the resultant dataframe will be
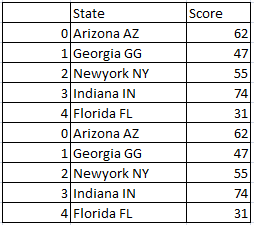
![]()
![]()



")

