Drop rows in R with conditions can be done with the help of subset () function. Let’s see how to delete or drop rows with multiple conditions in R with an example. Drop rows with missing and null values is accomplished using omit(), complete.cases() and slice() function. Drop rows by row index (row number) and row name in R
- remove or drop rows with condition in R using subset function
- remove or drop rows with null values or missing values using omit(), complete.cases() in R
- drop rows with slice() function in R dplyr package
- drop duplicate rows in R using dplyr using unique() and distinct() function
- delete or drop rows based on row number i.e. row index in R
- delete or drop rows based on row name in R
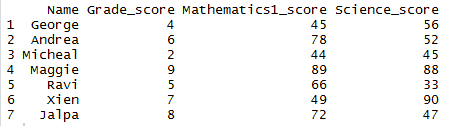
Let’s first create the dataframe.
# create dataframe
df1 = data.frame(Name = c('George','Andrea', 'Micheal','Maggie','Ravi','Xien','Jalpa'),
Grade_score=c(4,6,2,9,5,7,8),
Mathematics1_score=c(45,78,44,89,66,49,72),
Science_score=c(56,52,45,88,33,90,47))
df1
So the resultant dataframe will be
Delete or Drop rows in R with conditions:
Method 1:
Delete rows with name as George or Andrea
df2<-df1[!(df1$Name=="George" | df1$Name=="Andrea"),] df2
Resultant dataframe will be

Method 2: drop rows using subset() function
Drop rows with conditions in R using subset function.
df2<-subset(df1, Name!="George" & Name!="Andrea") df2
Resultant dataframe will be

Method 3: using slice() function in dplyr package of R
Drop rows with conditions in R using slice() function.
### Drop rows using slice() function in R library(dplyr) df2 <- df1 %>% slice(-c(2, 4, 6)) df2
Resultant dataframe with 2nd, 4th and 6th rows removed as shown below
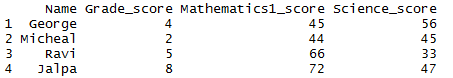
Drop Rows by row name and Row number (Row index) in R:
Drop Row by row number or row index:
Dropping or removing Rows by row number or Row index in R can be accomplished either by slice() function and also by the ‘-‘ operator.
### Drop rows using slice() function in R library(dplyr) df2 <- df1 %>% slice(-c(2, 4, 6)) df2
OR
### Drop rows using "-" operator in R df2 <- df1[-c(2, 4, 6), ] df2
Resultant dataframe with 2nd, 4th and 6th rows removed as shown below
Drop Row by row name :
Drop Rows by row name or Row index in R can be accomplished either by slice() function and also by the ‘-‘ operator.
### Drop rows using slice() function in R
library(dplyr)
df1[!(row.names(df1) %in% c('1','2')), ]
Row names are nothing but row index numbers in this case

Drop rows with missing values in R (Drop NA, Drop NaN) :
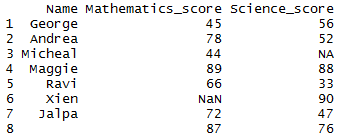
Let’s first create the dataframe with NA values as shown below
df1 = data.frame(Name = c('George','Andrea', 'Micheal','Maggie','Ravi','Xien','Jalpa',''),
Mathematics_score=c(45,78,44,89,66,NaN,72,87),
Science_score=c(56,52,NA,88,33,90,47,76))
df1
dataframe will be
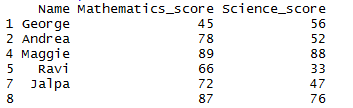
Method 1: Remove or Drop rows with NA using omit() function:
Using na.omit() to remove rows with (missing) NA and NaN values
df1_complete = na.omit(df1) # Method 1 - Remove NA df1_complete
so after removing NA and NaN the resultant dataframe will be
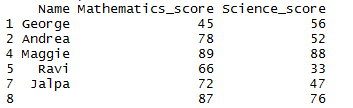
Method 2: Remove or Drop rows with NA using complete.cases() function
Using complete.cases() to remove rows with (missing) NA and NaN values
df1[complete.cases(df1),]
so after removing NA and NaN the resultant dataframe will be
Removing Both Null and missing:
By subsetting each column with non NAs and not null is round about way to remove both Null and missing values as shown below
# Remove null & NA values df1[!(is.na(df1$Name) | df1$Name=="" | is.na(df1$Science_score) | df1$Science_score==""|is.na(df1$Mathematics_score) | df1$Mathematics_score==""),]
so after removing Null, NA and NaN the resultant dataframe will be

Drop Duplicate row in R :
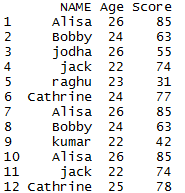
We will be using the following dataframe to depict the drop duplicates in R. Lets first create the dataframe.
# simple Data frame creation
mydata = data.frame (NAME =c ('Alisa','Bobby','jodha','jack','raghu','Cathrine',
'Alisa','Bobby','kumar','Alisa','jack','Cathrine'),
Age = c (26,24,26,22,23,24,26,24,22,26,22,25),
Score =c(85,63,55,74,31,77,85,63,42,85,74,78))
mydata
so the resultant data frame will be
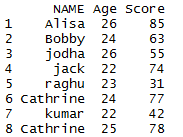
distinct() Function in Dplyr – Remove duplicate rows of a dataframe in R:
library(dplyr) # Remove duplicate rows of the dataframe distinct(mydata)
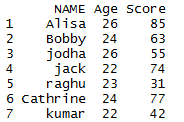
In this dataset, all the duplicate rows are removed so it returns the unique rows in mydata.
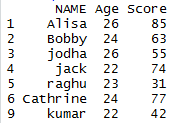
DROP Duplicates in R using unique() function in R:
When we apply unique function to the above data frame
## Apply unique function for data frame in R unique(mydata)
Duplicate entries in the data frame are eliminated and the final output will be
Remove Duplicates based on a column using duplicated() function:
duplicated() function along with [!] takes up the column name as argument and results in identifying unique value of the particular column as shown below
## unique value of the column in R dataframe mydata[!duplicated(mydata$NAME), ]
so the dataframe with unique values of the NAME column will be
Other Related Topics:
![]()
![]()



 in R using Dplyr – select () Function")

