In this section we will see how to find duplicate rows in PostgreSQL table. To find duplicate rows in a PostgreSQL table, you can use the GROUP BY clause along with the HAVING Getting duplicate rows in PostgreSQL table can be accomplished by using multiple methods each is explained with an example.
- Find the rows that have duplicate values in single column in PostgreSQL
- Find the rows that have duplicate values in multiple columns in PostgreSQL
- Find duplicate rows of entire table in PostgreSQL
- Display all the duplicate rows in postgresql
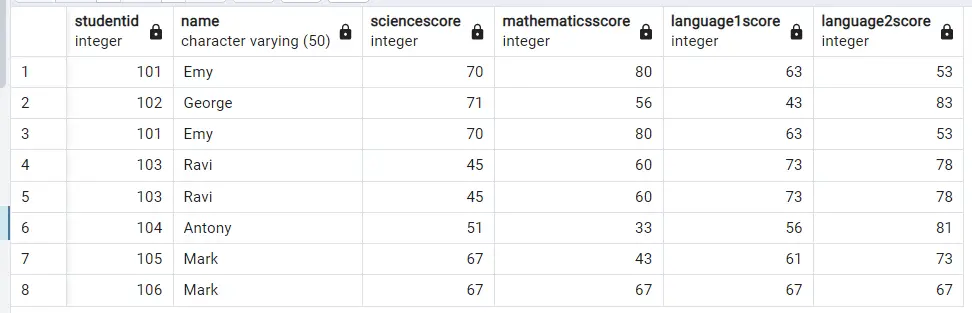
The table which we use for depiction is
examscore_dup:
Extract Duplicate Rows in PostgreSQL Table:
Method 1: using group by and having
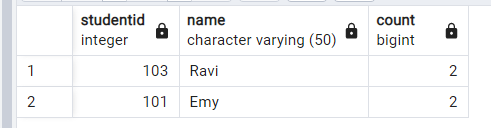
select distinct * from examscore_dup where studentid in ( select studentid from ( select studentid, count(*) from examscore_dup group by studentid HAVING count(*) > 1) as foo);
We have chosen duplicate row by counting the number of rows for each studentid and chosen the rows having count > 1.
Output:

Method 2: Find Duplicate Rows in PostgreSQL with partition by
We have chosen duplicate row by partition by and order by as shown below
select distinct * from examscore_dup where studentid in ( select studentid from ( select studentid, ROW_NUMBER() OVER(PARTITION BY studentid ORDER BY studentid asc) AS Row FROM examscore_dup ) as foo where foo.Row > 1);
OUTPUT:

Display all Duplicate rows:
Displaying all duplicate rows without any deduplication can be achieved through below code.
SELECT * FROM examscore_dup WHERE (studentid, name) IN ( SELECT studentid, name FROM examscore_dup GROUP BY name, studentid HAVING COUNT(*) > 1 );
The above query will produce all the duplicate rows as such; If the duplicate is appearing thrice all the three rows will be displayed
Output:

Extract Duplicate Rows in the single column in postgreSQL:
To find duplicates based on a single column, such as name, you can use the following query
SELECT name, COUNT(*) FROM examscore_dup GROUP BY name HAVING COUNT(*) > 1;
This query groups the rows by the name column and counts the number of occurrences for each name. The HAVING COUNT(*) > 1 clause filters the results to show only those name that appear more than once.
Output:
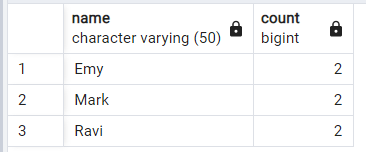
Finding Duplicates Based on Multiple Columns in postgreSQL:
To find duplicate rows based on multiple columns, such as name and studentid, you can use a similar approach:
SELECT studentid,name, COUNT(*) FROM examscore_dup GROUP BY studentid,name HAVING COUNT(*) > 1;
This query groups the rows by both the name and studentid columns and counts the number of occurrences for each combination. The HAVING COUNT(*) > 1 clause filters the results to show only those combinations that appear more than once.
Output: