In this tutorial we will learn how to get the unique values (distinct rows) of a dataframe in python pandas with drop_duplicates() function. Lets see with an example on how to drop duplicates and get Distinct rows of the dataframe in pandas python.
- Get distinct rows of dataframe in pandas python by dropping duplicates
- Get distinct value of the dataframe in pandas by particular column
- Drop Duplicate in pandas on case sensitive values of dataframe

- Keep only non duplicated values of the dataframe in pandas case sensitive
#### Create Dataframe:
import pandas as pd
import numpy as np
#Create a DataFrame
d = {
'Name':['Alisa','Bobby','jodha','jack','raghu','Cathrine',
'Alisa','Bobby','kumar','Alisa','Alex','Cathrine'],
'Age':[26,24,23,22,23,24,26,24,22,23,24,24]
}
df = pd.DataFrame(d,columns=['Name','Age'])
df
so the output will be
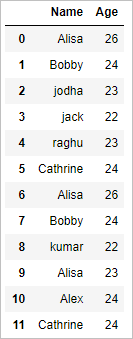
Get the unique values (distinct rows) of the dataframe in python pandas
drop_duplicates() function is used to get the unique values (rows) of the dataframe in python pandas.
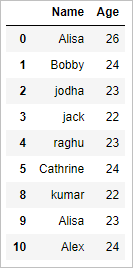
# get the unique values (rows) df.drop_duplicates()
The above drop_duplicates() function removes all the duplicate rows and returns only unique rows. Generally it retains the first row when duplicate rows are present.
So the output will be
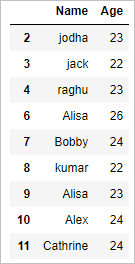
Get the unique values (rows) of the dataframe in python pandas by retaining last row:
# get the unique values (rows) by retaining last row df.drop_duplicates(keep='last')
The above drop_duplicates() function with keep =’last’ argument, removes all the duplicate rows and returns only unique rows by retaining the last row when duplicate rows are present.
So the output will be
Get the unique values (rows) of the dataframe in python pandas by retaining first row:
# get the unique values (rows) by retaining first row df.drop_duplicates(keep='first')
The above drop_duplicates() function with keep =’first’ argument, removes all the duplicate rows and returns only unique rows by retaining the first row when duplicate rows are present.
So the output will be
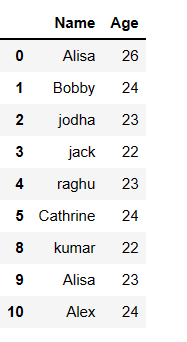
Remove all Duplicate rows and keep only non repeating rows :
In order to keep only non repeating rows, i.e. retaining only non duplicate rows we can use drop_duplicate() function with keep=False as shown below
# Remove all duplicate rows ## Get all non repeating rows in pandas. - non duplicate rows df.drop_duplicates(keep=False)
The result will have only non repeating rows of the dataframe (non duplicate rows) in pandas
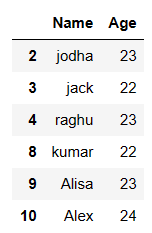
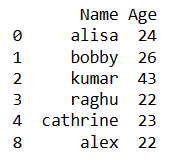
Get Distinct values of the dataframe based on a column:
In this we will subset a column and extract distinct values of the dataframe based on that column.
# get distinct values of the dataframe based on column df = df.drop_duplicates(subset = ["Age"]) df
So the resultant dataframe will have distinct values based on “Age” column
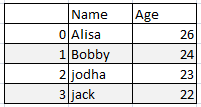
Drop Duplicate in pandas on case sensitive values of dataframe :
Lets create the sample dataframe
#### Create Dataframe:
import pandas as pd
import numpy as np
#Create a DataFrame
d = {
'Name':['Alisa','Bobby','kumar','raghu','CATHRINE',
'ALISA','BOBBY','KUMAR','Alex','Cathrine'],
'Age':[24,26,43,22,23,24,26,43,22,23]
}
df = pd.DataFrame(d,columns=['Name','Age'])
df
dataframe will be
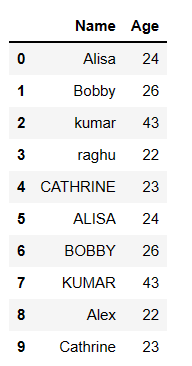
First, convert all the string values to lowercase or upper case to make them case insensitive and then deduplicate the dataframe using drop_duplicate in pandas
### Drop duplicates in pandas case insensitive df2 = df.apply(lambda x: x.astype(str).str.lower()).drop_duplicates(subset=['Name'], keep='first') print(df2)
we used apply function and first converted the string to lower case and then apply drop_duplicates() function and
removed duplicates by retaining the first row when duplicates are present,
So the resultant dataframe will have distinct rows.
Keep only non duplicated values of dataframe in pandas case sensitive
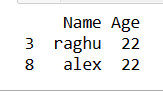
First convert the values in either uppercase or lower case and then keep only non duplicated values using drop_duplicate() with KEEP=False in pandas
### keep only non duplicated values in pandas case insensitive df2 = df.apply(lambda x: x.astype(str).str.lower()).drop_duplicates(subset=['Name'], keep=False) print(df2)
So the resultant dataframe will have only non repeating rows.
![]()
![]()
")

 function")


