In order to get the distinct rows of dataframe in pyspark we will be using distinct() function. There is another way to drop the duplicate rows of the dataframe in pyspark using dropDuplicates() function, there by getting distinct rows of dataframe in pyspark. drop duplicates by multiple columns in pyspark, drop duplicate keep last and keep first occurrence rows etc. Let’s see with an example on how to get distinct rows in pyspark
- Distinct value of dataframe in pyspark using distinct() function.
- Drop duplicates in pyspark and thereby getting distinct rows – dropDuplicates()
- Drop duplicates by a specific column in pyspark
- Drop duplicates on conditions in pyspark .
- orderby and drop duplicate rows in pyspark
- Drop duplicate rows and keep last occurrences
- Drop duplicate rows and keep first occurrences
- Distinct value of a column in pyspark
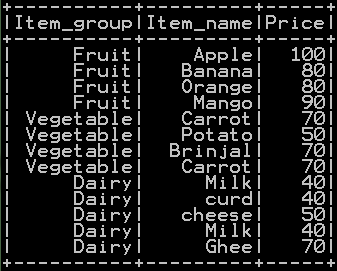
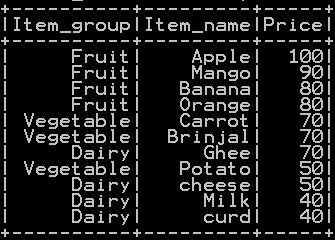
We will be using dataframe df_basket
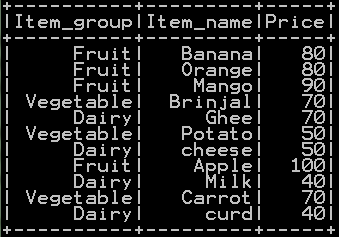
Get distinct value of dataframe in pyspark – distinct rows – Method 1
Our first method is selecting the distinct value of the dataframe in pyspark
Syntax:
df – dataframe
dataframe.distinct() gets the distinct value of the dataframe in pyspark
### Get distinct value of dataframe – distinct row in pyspark df_basket.distinct().show()
Distinct value of “df_basket” dataframe will be
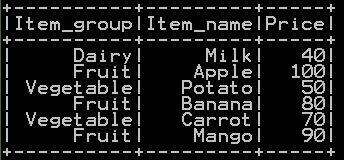
Drop duplicates in pyspark – get distinct rows – Method 2
Our second method is to drop the duplicates and there by only distinct rows left in the dataframe as shown below.
Syntax:
df – dataframe
dataframe.dropDuplicates() removes the duplicate value of the dataframe and thereby keeps only distinct value of the dataframe in pyspark
### Get distinct value of dataframe – distinct row in pyspark df_basket.dropDuplicates().show()
Distinct value of “df_basket” dataframe by using dropDuplicate() function will be
Drop duplicate rows in pyspark by a specific column:
dataframe.dropDuplicates() takes the column name as argument and removes duplicate value of that particular column thereby distinct value of column is obtained.
### drop duplicates by specific column df_basket.dropDuplicates((['Price'])).show()
dataframe with duplicate value of column “Price” removed will be
Get distinct value of a column in pyspark – distinct()
Distinct value of the column is obtained by using select() function along with distinct() function. select() function takes up the column name as argument, Followed by distinct() function will give distinct value of the column
### Get distinct value of column
df_basket.select("Item_group").distinct().show()
distinct value of “Item_group” column will be
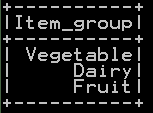
Drop duplicate rows and orderby in pyspark:
dataframe.dropDuplicates() removes/drops duplicate rows of the dataframe and orderby() function takes up the column name as argument and thereby orders the column in either ascending or descending order.
### drop duplicates and order by
df_basket.orderBy(F.col("Price").desc()).dropDuplicates().show()
dataframe with duplicate rows dropped and the ordered by “Price” column will be
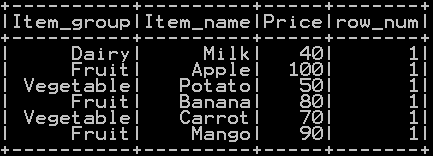
Drop duplicate rows by keeping the first duplicate occurrence in pyspark:
dropping duplicates by keeping first occurrence is accomplished by adding a new column row_num (incremental column) and drop duplicates based the min row after grouping on all the columns you are interested in.(you can include all the columns for dropping duplicates except the row num col)
### drop duplicates and keep first occurrence
from pyspark.sql.window import Window
import pyspark.sql.functions as F
from pyspark.sql.functions import row_number
df_basket1 = df_basket.select("Item_group","Item_name","Price", F.row_number().over(Window.partitionBy("Price").orderBy(df_basket['price'])).alias("row_num"))
df_basket1.filter(df_basket1.row_num ==1).show()
dropping duplicates by keeping first occurrence is
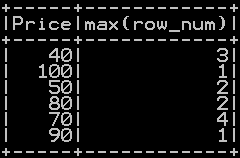
Drop duplicate rows by keeping the Last duplicate occurrence in pyspark:
dropping duplicates by keeping last occurrence is accomplished by adding a new column row_num (incremental column) and drop duplicates based the max row after grouping on all the columns you are interested in.(you can include all the columns for dropping duplicates except the row num col)
### drop duplicates and keep last occurrence
from pyspark.sql.window import Window
import pyspark.sql.functions as F
from pyspark.sql.functions import row_number,rank,col
df_basket1 = df_basket.select("Item_group","Item_name","Price", F.row_number().over(Window.partitionBy("Price").orderBy(df_basket['price'])).alias("row_num"))
df_basket1.groupBy("Price").max("row_num").show()
dropping duplicates by keeping last occurrence is
Other Related Topics:
- Count of Missing (NaN,Na) and null values in Pyspark
- Mean, Variance and standard deviation of column in Pyspark
- Maximum or Minimum value of column in Pyspark
- Raised to power of column in pyspark – square, cube , square root and cube root in pyspark
- Drop column in pyspark – drop single & multiple columns
- Subset or Filter data with multiple conditions in pyspark
- Frequency table or cross table in pyspark – 2 way cross table
- Groupby functions in pyspark (Aggregate functions) – Groupby count, Groupby sum, Groupby mean, Groupby min and Groupby max
- Descriptive statistics or Summary Statistics of dataframe in pyspark
- Rearrange or reorder column in pyspark
- cumulative sum of column and group in pyspark
- Calculate Percentage and cumulative percentage of column in pyspark
- Select column in Pyspark (Select single & Multiple columns)
- Get data type of column in Pyspark (single & Multiple columns)
![]()
![]()


")
")

")