In order to calculate cumulative sum of column in pyspark we will be using sum function and partitionBy. To calculate cumulative sum of a group in pyspark we will be using sum function and also we mention the group on which we want to partitionBy lets get clarity with an example.
- Calculate cumulative sum of column in pyspark using sum() function
- Calculate cumulative sum of the column by group in pyspark using sum() function and partitionby() function
- cumulative sum of the column in pyspark with NaN / Missing values/ null values
We will use the dataframe named df_basket1.

Calculate Cumulative sum of column in pyspark:
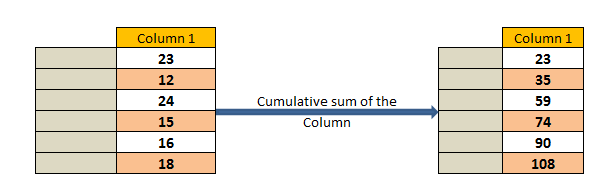
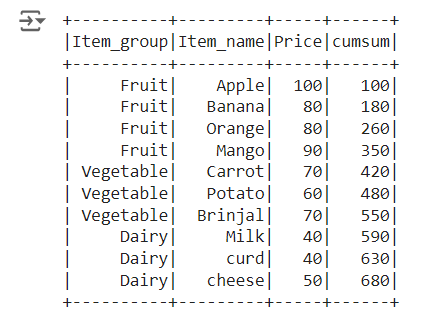
Sum() function and partitionBy() is used to calculate the cumulative sum of column in pyspark.
import sys
from pyspark.sql.window import Window
import pyspark.sql.functions as f
cum_sum = df_basket1.withColumn('cumsum', f.sum(df_basket1.Price).over(Window.partitionBy().orderBy().rowsBetween(-sys.maxsize, 0)))
cum_sum.show()
rowsBetween(-sys.maxsize, 0) along with sum function is used to create cumulative sum of the column and it is named as cumsum
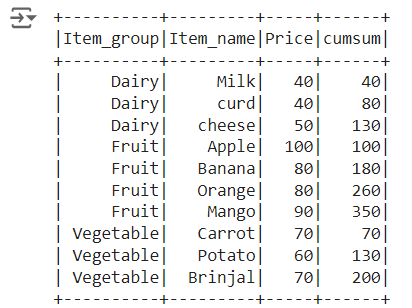
Calculate Cumulative sum of the column by Group in pyspark:
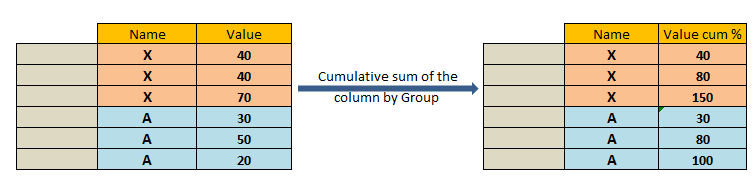
Sum() function and partitionBy a column name is used to calculate the cumulative sum of the “Price” column by group (“Item_group”) in pyspark
import sys
from pyspark.sql.window import Window
import pyspark.sql.functions as f
cum_sum = df_basket1.withColumn('cumsum', f.sum(df_basket1.Price).over(Window.partitionBy('Item_group').orderBy().rowsBetween(-sys.maxsize, 0)))
cum_sum.show()
rowsBetween(-sys.maxsize, 0) along with sum function is used to create cumulative sum of the column, an additional partitionBy() function of Item_group column calculates the cumulative sum of each group as shown below
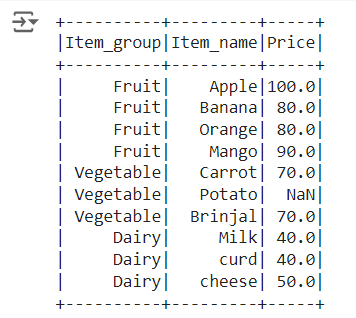
Cumulative sum of the column with NA/ missing /null values :
First lets look at a dataframe df_basket2 which has both null and NaN present which is shown below
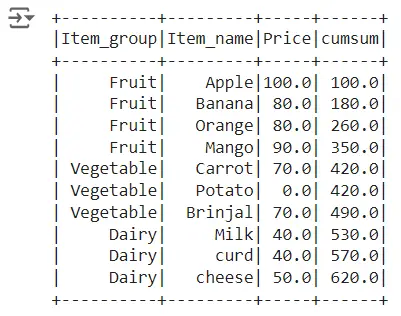
At First we will be replacing the missing and NaN values with 0, using fill.na(0) ; then will use Sum() function and partitionBy a column name is used to calculate the cumulative sum of the “Price” column
#### cumulative sum with NA and missing
import sys
from pyspark.sql.window import Window
import pyspark.sql.functions as f
df_basket2=df_basket2.fillna(0)
cum_sum = df_basket2.withColumn('cumsum', f.sum(df_basket2.Price).over(Window.partitionBy().orderBy().rowsBetween(-sys.maxsize, 0)))
cum_sum.show()
rowsBetween(-sys.maxsize, 0) along with sum function is used to create cumulative sum of the column as shown below
Other Related Topics:
- Simple random sampling and stratified sampling in pyspark – Sample(), SampleBy()
- Rearrange or reorder column in pyspark
- Join in pyspark (Merge) inner , outer, right , left join in pyspark
- Get duplicate rows in pyspark
- Quantile rank, decile rank & n tile rank in pyspark – Rank by Group
- Populate row number in pyspark – Row number by Group
- Percentile Rank of the column in pyspark
- Mean of two or more columns in pyspark
- Sum of two or more columns in pyspark
- Row wise mean, sum, minimum and maximum in pyspark
- Rename column name in pyspark – Rename single and multiple column.
![]()
![]()

 and null values in Pyspark")



")