In order to populate row number in pyspark we use row_number() Function. row_number() function along with partitionBy() of other column populates the row number by group. Let’s see an example on how to populate row number in pyspark and also we will look at an example of populating row number for each group.
- Populate row number in pyspark – using row_number() function.
- Populate row number in pyspark by group – using row_number() along with partitionBy() function.
We will be using the dataframe df_basket1
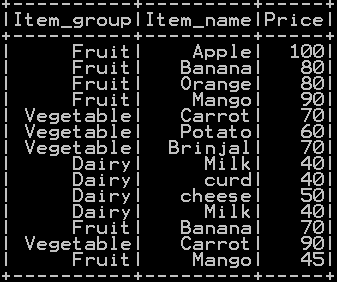
Populating Row number in pyspark:
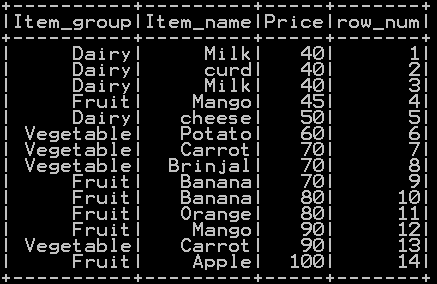
Row number is populated by row_number() function. We will be using partitionBy(), orderBy() on a column so that row number will be populated. partitionBy() function does not take any argument as we are not grouping by any variable. As the result row number is populated and stored in the new column named “row_num” as shown below.
### Row number in pyspark
from pyspark.sql.window import Window
import pyspark.sql.functions as F
from pyspark.sql.functions import row_number
df_basket1 = df_basket1.select("Item_group","Item_name","Price", F.row_number().over(Window.partitionBy().orderBy(df_basket1['price'])).alias("row_num"))
df_basket1.show()
So the resultant row number populated dataframe in pyspark will be
Populate row number in pyspark by group
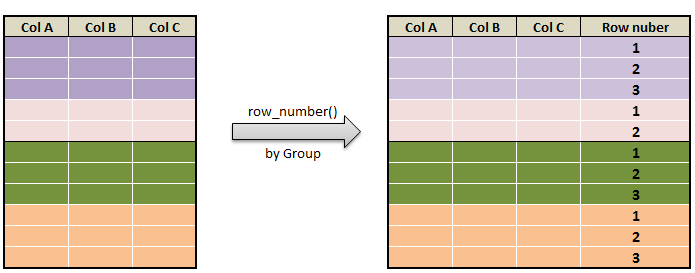
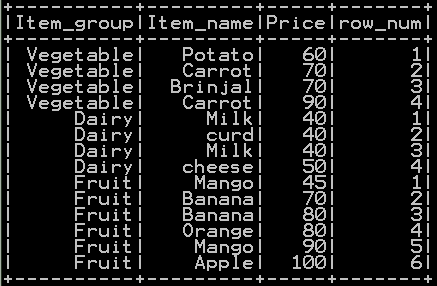
Row number by group is populated by row_number() function. We will be using partitionBy() on a group, orderBy() on a column so that row number will be populated by group in pyspark. partitionBy() function takes the column name as argument on which we have to make the grouping . In our case grouping done on “Item_group” As the result row number is populated by “Item_group” and the result is stored in the new column named “row_num” as shown below.
### Row number in pyspark by group
from pyspark.sql.window import Window
import pyspark.sql.functions as F
from pyspark.sql.functions import row_number
df_basket1 = df_basket1.select("Item_group","Item_name","Price", F.row_number().over(Window.partitionBy(df_basket1['Item_group']).orderBy(df_basket1['price'])).alias("row_num"))
df_basket1.show()
So the resultant dataframe with row number populated by group will be
Other Related Topics:
- Percentile Rank of the column in pyspark
- Mean of two or more columns in pyspark
- Sum of two or more columns in pyspark
- Row wise mean, sum, minimum and maximum in pyspark
- Rename column name in pyspark – Rename single and multiple column
- Typecast Integer to Decimal and Integer to float in Pyspark
- Get number of rows and number of columns of dataframe in pyspark
- Extract Top N rows in pyspark – First N rows
- Absolute value of column in Pyspark – abs() function
- Set Difference in Pyspark – Difference of two dataframe
- Union and union all of two dataframe in pyspark (row bind)
- Intersect of two dataframe in pyspark (two or more)
- Round up, Round down and Round off in pyspark – (Ceil & floor pyspark)
- Sort the dataframe in pyspark – Sort on single column & Multiple column
![]()
![]()



")