In order to Extract First N rows in pyspark we will be using functions like show() function and head() function. head() function in pyspark returns the top N rows. Number of rows is passed as an argument to the head() and show() function. First() Function in pyspark returns the First row of the dataframe. To Extract Last N rows we will be working on roundabout methods like creating index and sorting them in reverse order and there by extracting bottom n rows, Let’s see how to
- Extract First row of dataframe in pyspark – using first() function.
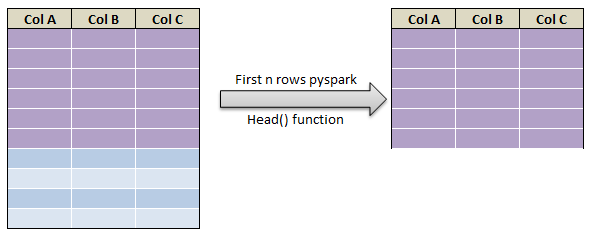
- Get First N rows in pyspark – Top N rows in pyspark using head() function – (First 10 rows)
- Get First N rows in pyspark – Top N rows in pyspark using take() and show() function
- Fetch Last Row of the dataframe in pyspark
- Extract Last N rows of the dataframe in pyspark – (Last 10 rows)
With an example for each
We will be using the dataframe named df_cars
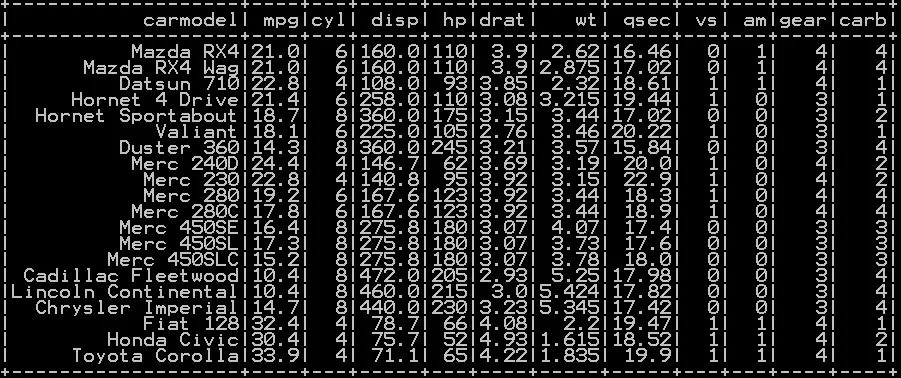
Get First N rows in pyspark
Extract First row of dataframe in pyspark – using first() function:
dataframe.first() Function extracts the first row of the dataframe
########## Extract first row of the dataframe in pyspark df_cars.first()
so the first row of “df_cars” dataframe is extracted
![]()
Extract First N rows in pyspark – Top N rows in pyspark using show() function:
dataframe.show(n) Function takes argument “n” and extracts the first n row of the dataframe
########## Extract first N row of the dataframe in pyspark – show() df_cars.show(5)
so the first 5 rows of “df_cars” dataframe is extracted

Extract First N rows in pyspark – Top N rows in pyspark using head() function:
dataframe.head(n) Function takes argument “n” and extracts the first n row of the dataframe
########## Extract first N row of the dataframe in pyspark – head() df_cars.head(3)
so the first 3 rows of “df_cars” dataframe is extracted

Extract First N rows in pyspark – Top N rows in pyspark using take() function:
dataframe.take(n) Function takes argument “n” and extracts the first n row of the dataframe
########## Extract first N row of the dataframe in pyspark – take() df_cars.take(2)
so the first 2 rows of “df_cars” dataframe is extracted

Extract Last N rows in Pyspark :
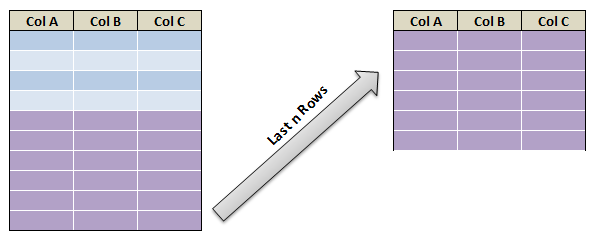
Extract Last row of dataframe in pyspark – using last() function:
last() Function extracts the last row of the dataframe and it is stored as a variable name “expr” and it is passed as an argument to agg() function as shown below.
########## Extract last row of the dataframe in pyspark from pyspark.sql import functions as F expr = [F.last(col).alias(col) for col in df_cars.columns] df_cars.agg(*expr).show()
so the last row of “df_cars” dataframe is extracted

Get Last N rows in pyspark:
Extracting last N rows of the dataframe is accomplished in a roundabout way. First step is to create a index using monotonically_increasing_id() Function and then as a second step sort them on descending order of the index. which in turn extracts last N rows of the dataframe as shown below.
########## Extract last N rows of the dataframe in pyspark
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.functions import desc
df_cars = df_cars.withColumn("index", monotonically_increasing_id())
df_cars.orderBy(desc("index")).drop("index").show(5)
so the last N rows of “df_cars” dataframe is extracted

Other Related topics:
- Sort the dataframe in pyspark – Sort on single column & Multiple column
- Drop rows in pyspark – drop rows with condition
- Distinct value of a column in pyspark
- Distinct value of dataframe in pyspark – drop duplicates
- Count of Missing (NaN,Na) and null values in Pyspark
- Mean, Variance and standard deviation of column in Pyspark
- Maximum or Minimum value of column in Pyspark
- Raised to power of column in pyspark – square, cube , square root and cube root in pyspark
- Drop column in pyspark – drop single & multiple columns
- Subset or Filter data with multiple conditions in pyspark
- Frequency table or cross table in pyspark – 2 way cross table
- Groupby functions in pyspark (Aggregate functions) – Groupby count, Groupby sum, Groupby mean, Groupby min and Groupby max
- Descriptive statistics or Summary Statistics of dataframe in pyspark.
![]()
![]()
, tail(), slice(),top_n() function in R")


")


