Raised to the power column in pyspark can be accomplished using pow() function with argument column name followed by numeric value which is raised to the power. with the help of pow() function we will be able to find the square value of the column, cube of the column , square root and cube root of the column in pyspark. We will see Raised to power of column in pyspark with an example
- Raised to power n of the column in pyspark with example
- Square of the column in pyspark with example
- Cube of the column in pyspark with example
- Square root of the column in pyspark with example
- Cube root of the column in pyspark with example
Syntax:
col1 – Column name
n – Raised power
We will be using df.
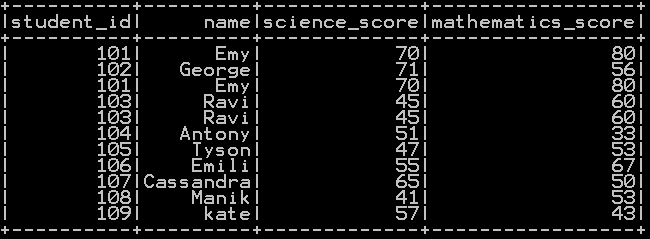
Square of the column in pyspark with example:
Pow() Function takes the column name and 2 as argument which calculates the square of the column in pyspark
## square of the column in pyspark
from pyspark.sql import Row
from pyspark.sql.functions import pow, col
df.select("*", pow(col("mathematics_score"), 2).alias("Math_score_square")).show()
In our example square of “mathematics_score” is calculated as shown below.
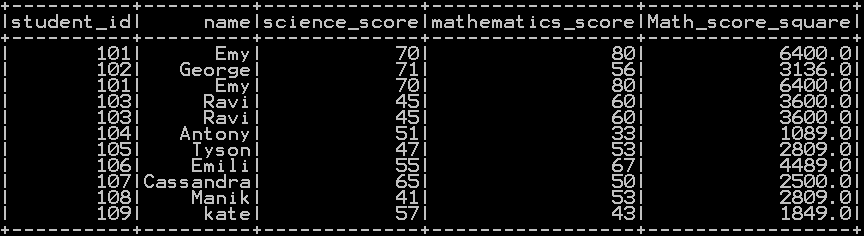
Cube of the column in pyspark with example:
Pow() Function takes the column name and 3 as argument which calculates the cube of the column in pyspark
## cube of the column in pyspark
from pyspark.sql import Row
from pyspark.sql.functions import pow, col
df.select("*", pow(col("mathematics_score"), 3).alias("Math_score_cube")).show()
In our example cube of “mathematics_score” is calculated as shown below.
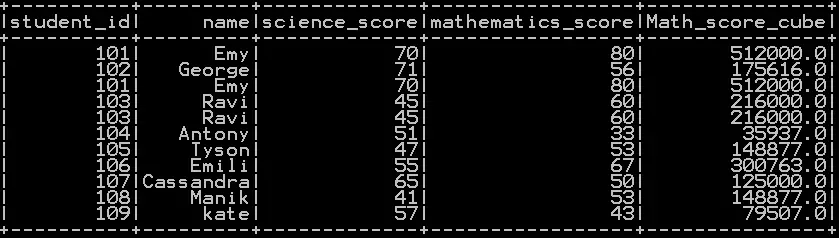
Power of N to the column in pyspark with example:
Pow() Function takes the column name and N as argument which calculates the Nth power of the column in pyspark
## Power of N to the column in pyspark
from pyspark.sql import Row
from pyspark.sql.functions import pow, col
df.select("*", pow(col("mathematics_score"), 4).alias("Math_score_power")).show()
In our example power of 4 is raised to the column “mathematics_score” as shown below.
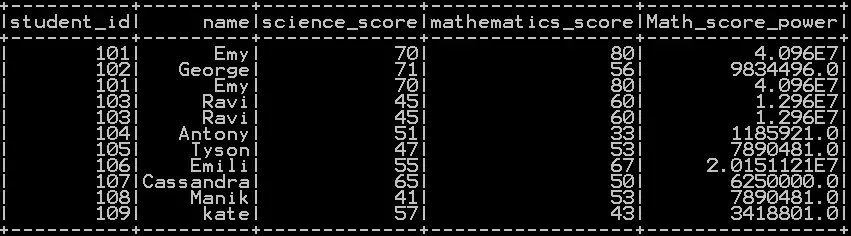
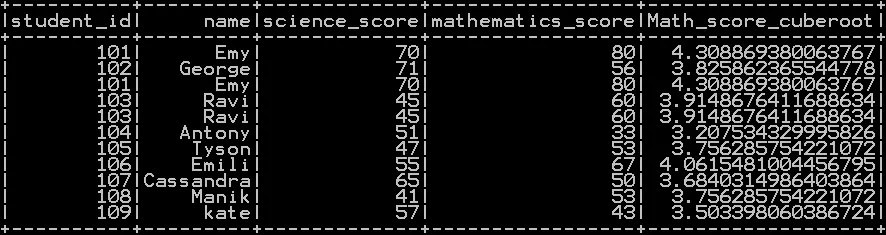
Cube root of the column in pyspark with example:
Pow() Function takes the column name and 1/3 as argument which calculates the cube root of the column in pyspark
## cube root of the column in pyspark
from pyspark.sql import Row
from pyspark.sql.functions import pow, col
df.select("*", pow(col("mathematics_score"), 1/3).alias("Math_score_cuberoot")).show()
In our example cube root of “mathematics_score” is calculated as shown below.
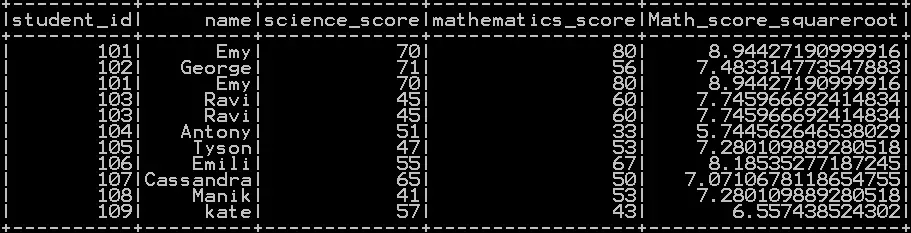
Square root of the column in pyspark with example:
Pow() Function takes the column name and 1/2 as argument which calculates the square root of the column in pyspark
## square root of the column in pyspark
from pyspark.sql import Row
from pyspark.sql.functions import pow, col
df.select("*", pow(col("mathematics_score"), 1/2).alias("Math_score_squareroot")).show()
In our example square root of “mathematics_score” is calculated as shown below.
Other Related Topics:
- Round up, Round down and Round off in pyspark – (Ceil & floor pyspark)
- Sort the dataframe in pyspark – Sort on single column & Multiple column
- Drop rows in pyspark – drop rows with condition
- Distinct value of a column in pyspark
- Distinct value of dataframe in pyspark – drop duplicates
- Count of Missing (NaN,Na) and null values in Pyspark
- Mean, Variance and standard deviation of column in Pyspark
- Maximum or Minimum value of column in Pyspark
- Raised to power of column in pyspark – square, cube , square root and cube root in pyspark
- Drop column in pyspark – drop single & multiple columns
- Subset or Filter data with multiple conditions in pyspark
- Frequency table or cross table in pyspark – 2 way cross table
- Groupby functions in pyspark (Aggregate functions) – Groupby count, Groupby sum, Groupby mean, Groupby min and Groupby max
- Descriptive statistics or Summary Statistics of dataframe in pyspark
- Rearrange or reorder column in pyspark
- cumulative sum of column and group in pyspark
- Calculate Percentage and cumulative percentage of column in pyspark
![]()
![]()




