In order to drop rows in pyspark we will be using different functions in different circumstances. Drop rows with condition in pyspark are accomplished by dropping – NA rows, dropping duplicate rows and dropping rows by specific conditions in a where clause etc. Let’s see an example for each on dropping rows in pyspark with multiple conditions.
- Drop rows with NA or missing values in pyspark
- Drop rows with Null values using where condition in pyspark
- Drop duplicate rows in pyspark
- Drop Duplicate rows by keeping the first occurrence in pyspark
- Drop duplicate rows by keeping the last occurrence in pyspark
- Drop rows with conditions using where clause
- Drop duplicate rows by a specific column
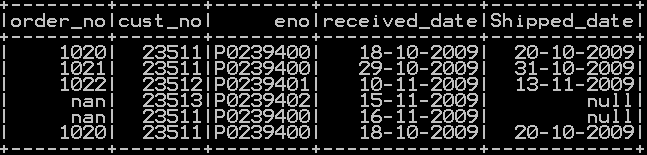
We will be using dataframe df_orders
Drop rows with NA or missing values in pyspark : Method1
Drop rows with NA or missing values in pyspark is accomplished by using dropna() function.
### Drop rows with NA or missing values in pyspark df_orders1=df_orders.dropna() df_orders1.show()
NA or Missing values in pyspark is dropped using dropna() function.

Drop rows with NA or missing values in pyspark : Method2
Drop rows with NA or missing values in pyspark is accomplished by using na.drop() function.
### Drop rows with NA or missing values in pyspark df_orders.na.drop().show()
NA or Missing values in pyspark is dropped using na.drop() function.
Drop NULL rows with where condition in pyspark :
Drop rows with Null values values in pyspark is accomplished by using isNotNull() function along with where condition rows with Non null values are filtered using where condition as shown below.
### Drop rows with Null values with where condition in pyspark
df_orders1 = df_orders.where(col('Shipped_date').isNotNull())
df_orders1.show()
Null values values in pyspark is dropped using isNotNull() function.
Drop duplicate rows in pyspark:
Duplicate rows of dataframe in pyspark is dropped using dropDuplicates() function.
#### Drop rows in pyspark – drop duplicate rows from pyspark.sql import Row df_orders1 = df_orders.dropDuplicates() df_orders1.show()
dataframe.dropDuplicates() removes duplicate rows of the dataframe

Drop duplicate rows by a specific column
Duplicate rows is dropped by a specific column of dataframe in pyspark using dropDuplicates() function. dropDuplicates() with column name passed as argument will remove duplicate rows by a specific column
#### Drop duplicate rows in pyspark by a specific column df_orders.dropDuplicates((['cust_no'])).show()
dataframe.dropDuplicates(‘colname’) removes duplicate rows of the dataframe by a specific column

Drop duplicate rows by keeping the first duplicate occurrence in pyspark:
dropping duplicates by keeping first occurrence is accomplished by adding a new column row_num (incremental column) and drop duplicates based the min row after grouping on all the columns you are interested in.(you can include all the columns for dropping duplicates except the row num col)
### drop duplicates and keep first occurrence
from pyspark.sql.window import Window
import pyspark.sql.functions as F
from pyspark.sql.functions import row_number
df_orders1 = df_orders.select("order_no","cust_no","eno","received_date","Shipped_date", F.row_number().over(Window.partitionBy("received_date").orderBy(df_orders['received_date'])).alias("row_num"))
df_orders1.filter(df_orders1.row_num ==1).show()
dropping duplicates by keeping first occurrence is

Drop duplicate rows by keeping the Last duplicate occurrence in pyspark:
dropping duplicates by keeping last occurrence is accomplished by adding a new column row_num (incremental column) and drop duplicates based the max row after grouping on all the columns you are interested in.(you can include all the columns for dropping duplicates except the row num col)
### drop duplicates and keep last occurrence
from pyspark.sql.window import Window
import pyspark.sql.functions as F
from pyspark.sql.functions import row_number
df_orders1 = df_orders.select("order_no","cust_no","eno","received_date","Shipped_date", F.row_number().over(Window.partitionBy("received_date").orderBy(df_orders['received_date'])).alias("row_num"))
df_orders1.groupBy("order_no","cust_no","eno","received_date","Shipped_date").max("row_num").show()
dropping duplicates by keeping last occurrence is

Drop rows with conditions using where clause
Drop rows with conditions in pyspark is accomplished by using where() function. condition to be dropped is specified inside the where clause
#### Drop rows with conditions – where clause
df_orders1=df_orders.where("cust_no!=23512")
df_orders1.show()
dataframe with rows dropped after where clause will be

also for other function refer the cheatsheet.
Other Related Topics:
- Remove leading zero of column in pyspark
- Left and Right pad of column in pyspark –lpad() & rpad()
- Add Leading and Trailing space of column in pyspark – add space
- Remove Leading, Trailing and all space of column in pyspark – strip & trim space
- String split of the columns in pyspark
- Repeat the column in Pyspark
- Get Substring of the column in Pyspark
- Get String length of column in Pyspark
- Typecast string to date and date to string in Pyspark
- Typecast Integer to string and String to integer in Pyspark
- Extract First N and Last N character in pyspark
- Drop rows in pyspark – drop rows with condition
- Distinct value of a column in pyspark
- Distinct value of dataframe in pyspark – drop duplicates
- Count of Missing (NaN,Na) and null values in Pyspark
- Drop column in pyspark – drop single & multiple columns
- Convert to upper case, lower case and title case in pyspark
- Add leading zeros to the column in pyspark
- Concatenate two columns in pyspark
![]()
![]()
 and null values in Pyspark")




