Intersect of two dataframe in pyspark can be accomplished using intersect() function. Intersection in Pyspark returns the common rows of two or more dataframe. Intersect removes the duplicate after combining. Intersect all returns the common rows from the dataframe with duplicate.
Intersect of two dataframe in pyspark performs a DISTINCT on the result set, returns the common rows of two different tables
- Intersect of two dataframe in pyspark
- Intersect of two or more dataframe in pyspark – (more than two dataframe)
- Intersect all of the two or more dataframe – without removing the duplicate rows.
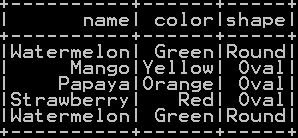
We will be using two dataframes namely df_summerfruits and df_fruits.
df_summerfruits:
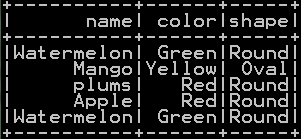
df_fruits:
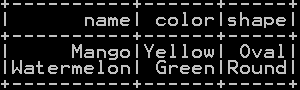
Intersect of two dataframe in pyspark
dataframe1.intersect(dataframe2) gets the common rows of dataframe1 and dataframe2. So the rows that are present in both dataframes will be returned
########## Intersect of two dataframe in pyspark df_inter=df_summerfruits.intersect(df_fruits) df_inter.show()
common rows present in both “df_summerfruits” and “df_fruits” dataframe is shown below
Intersect of two or more dataframe in pyspark
Intersect() function takes up more than two dataframes as argument and gets the common rows of all the dataframe.
############ intersect of more than two tables
from functools import reduce
from pyspark.sql import DataFrame
def intersect(*dfs):
return reduce(DataFrame.intersect, dfs)
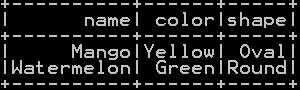
intersect(df_summerfruits, df_fruits, df_summerfruits).show()
Common rows present in “df_summerfruits” ,“df_fruits”, “df_summerfruits” dataframe is shown below
IntersectAll of the dataframe in pyspark:
Intersect all of the dataframe in pyspark is similar to intersect function but the only difference is it will not remove the duplicate rows of the resultant dataframe.
Intersectall() function takes up more than two dataframes as argument and gets the common rows of all the dataframe with duplicates not being eliminated.
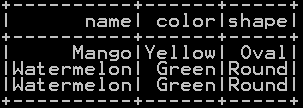
############ intersect all of more than two tables df_summerfruits.intersectAll(df_fruits).show()
Common rows present in both the dataframes “df_summerfruits” & “df_fruits”, without removing duplicate will be
Other Related Topics:
- Distinct value of dataframe in pyspark – drop duplicates
- Count of Missing (NaN,Na) and null values in Pyspark
- Mean, Variance and standard deviation of column in Pyspark
- Maximum or Minimum value of column in Pyspark
- Raised to power of column in pyspark – square, cube , square root and cube root in pyspark
- Drop column in pyspark – drop single & multiple columns
- Subset or Filter data with multiple conditions in pyspark
- Frequency table or cross table in pyspark – 2 way cross table
- Groupby functions in pyspark (Aggregate functions) – Groupby count, Groupby sum, Groupby mean, Groupby min and Groupby max
- Descriptive statistics or Summary Statistics of dataframe in pyspark
- Rearrange or reorder column in pyspark
- cumulative sum of column and group in pyspark
- Calculate Percentage and cumulative percentage of column in pyspark
- Select column in Pyspark (Select single & Multiple columns)
- Get data type of column in Pyspark (single & Multiple columns)
- Get List of columns and its data type in Pyspark
![]()
![]()

")

")

