Union all of two dataframe in pyspark can be accomplished using unionAll() function. unionAll() function row binds two dataframe in pyspark and does not removes the duplicates this is called union all in pyspark. Union of two dataframe can be accomplished in roundabout way by using unionall() function first and then remove the duplicate by using distinct() function and there by performing in union in roundabout way.
Note: Both UNION and UNION ALL in pyspark is different from other languages. Union will not remove duplicate in pyspark.
We will be demonstrating following with examples for each
- union of two dataframe in pyspark – union with distinct rows
- union of two or more dataframe – (more than two dataframes)
- union all of two dataframe in pyspark
- union all of more than two dataframe
Union pictographic representation:
pyspark union all: Union all concatenates but does not remove duplicates.
Union all pictographic representation:
Let’s discuss with an example. Let’s take three dataframe for example
We will be using three dataframes namely df_summerfruits, df_fruits, df_dryfruits
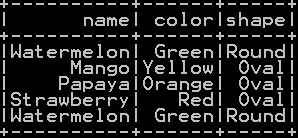
df_summerfruits:
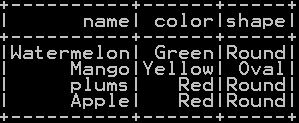
df_fruits:
df_dryfruits:
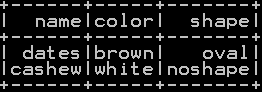
Union all of two dataframe without removing duplicates – Union ALL:
UnionAll() function unions or row binds two or more dataframe and does not remove duplicates
########## Union ALL of two dataframe in pyspark df_union_all=df_summerfruits.unionAll(df_fruits) df_union_all.show()
unionAll of “df_summerfruits” and “df_fruits” dataframe will be
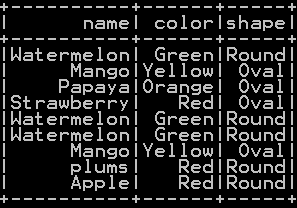
Union all of more than two dataframe in pyspark without removing duplicates – Union ALL:
UnionAll() function also takes up more than two dataframe as input and computes union or rowbinds those dataframe and does not remove duplicates
########## Union ALL of more than two dataframes in pyspark from functools import reduce from pyspark.sql import DataFrame def unionAll(*dfs): return reduce(DataFrame.unionAll, dfs) unionAll(df_summerfruits, df_fruits, df_dryfruits).show()
unionAll of “df_summerfruits” ,“df_fruits” and “df_dryfruits” dataframe will be
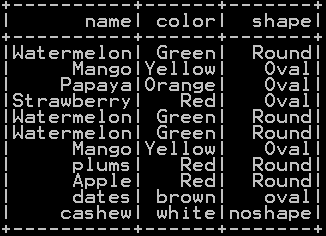
Union of two dataframe in pyspark after removing duplicates – Union:
UnionAll() function along with distinct() function takes two or more dataframes as input and computes union or rowbinding of those dataframe and removes duplicate rows.
########## Union of two dataframe in pyspark df_union=df_summerfruits.unionAll(df_fruits).distinct() df_union.show()
union of two dataframe is shown below
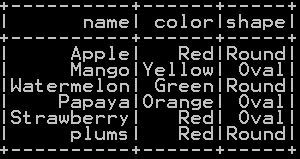
Union of more than two dataframe after removing duplicates – Union:
UnionAll() function along with distinct() function takes more than two dataframes as input and computes union or rowbinds those dataframes and distinct() function removes duplicate rows.
########## Union of more than two dataframe in pyspark from functools import reduce from pyspark.sql import DataFrame def unionAll(*dfs): return reduce(DataFrame.unionAll, dfs) unionAll(df_summerfruits, df_fruits, df_dryfruits).distinct().show()
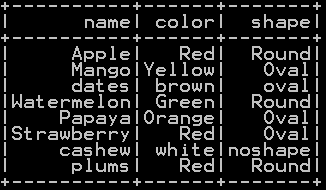
union of three dataframe with duplicates removed is shown below
Other Related Topics:
- Intersect of two dataframe in pyspark (two or more)
- Round up, Round down and Round off in pyspark – (Ceil & floor pyspark)
- Sort the dataframe in pyspark – Sort on single column & Multiple column
- Drop rows in pyspark – drop rows with condition
- Distinct value of a column in pyspark
- Distinct value of dataframe in pyspark – drop duplicates
- Count of Missing (NaN,Na) and null values in Pyspark
- Mean, Variance and standard deviation of column in Pyspark
- Maximum or Minimum value of column in Pyspark
- Raised to power of column in pyspark – square, cube , square root and cube root in pyspark
- Drop column in pyspark – drop single & multiple columns
- Subset or Filter data with multiple conditions in pyspark
- Frequency table or cross table in pyspark – 2 way cross table
![]()
![]()


")
 in R")
 function")
