In order to calculate the row wise mean, sum, minimum and maximum in pyspark, we will be using different functions. Row wise mean in pyspark is calculated in roundabout way. Row wise sum in pyspark is calculated using sum() function. Row wise minimum (min) in pyspark is calculated using least() function. Row wise maximum (max) in pyspark is calculated using greatest() function.
- Row wise mean in pyspark
- Row wise sum in pyspark
- Row wise minimum in pyspark
- Row wise maximum in pyspark
We will be using the dataframe df_student_detail.
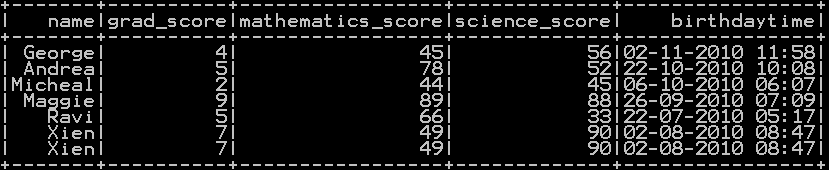
Row wise mean in pyspark : Method 1
We will be using simple + operator to calculate row wise mean in pyspark. using + to calculate sum and dividing by number of columns gives the mean
### Row wise mean in pyspark
from pyspark.sql.functions import col, lit
df1=df_student_detail.select(((col("mathematics_score") + col("science_score")) / lit(2)).alias("mean"))
df1.show()

Row wise mean in pyspark and appending it to dataframe: Method 2
In Method 2 we will be using simple + operator and dividing the result by number of columns to calculate row wise mean in pyspark, and appending the results to the dataframe
### Row wise mean in pyspark
from pyspark.sql.functions import col
df1=df_student_detail.withColumn("mean", (col("mathematics_score")+col("science_score"))/2)
df1.show()
So the resultant dataframe will be
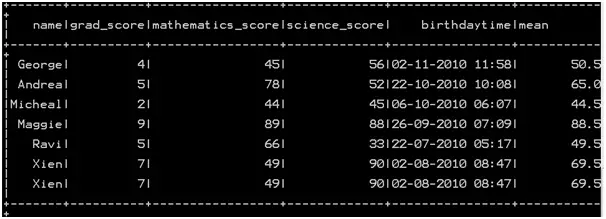
Row wise sum in pyspark : Method 1
We will be using simple + operator to calculate row wise sum in pyspark. We also use select() function to retrieve the result
### Row wise sum in pyspark
from pyspark.sql.functions import col
df1=df_student_detail.select(((col("mathematics_score") + col("science_score"))).alias("sum"))
df1.show()

Row wise sum in pyspark and appending to dataframe: Method 2
In Method 2 we will be using simple + operator to calculate row wise sum in pyspark, and appending the results to the dataframe by naming the column as sum
### Row wise sum in pyspark
from pyspark.sql.functions import col
df1=df_student_detail.withColumn("sum", col("mathematics_score")+col("science_score"))
df1.show()
So the resultant dataframe will be
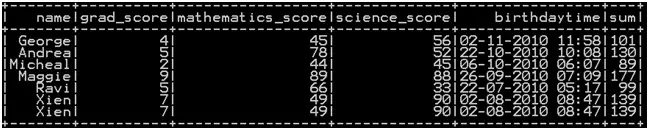
Row wise minimum in pyspark : Method 1
least() function takes the column name as arguments and calculates the row wise minimum value.
### Row wise minimum in pyspark
from pyspark.sql.functions import col, least
df1=df_student_detail.select((least(col("mathematics_score"),col("science_score"))).alias("minimum"))
df1.show()

Row wise minimum in pyspark : Method 2
In method 2 two we will be appending the result to the dataframe by using least function. least() function takes the column name as arguments and calculates the row wise minimum value and the result is appended to the dataframe
### Row wise minimum in pyspark
from pyspark.sql.functions import least
df1=df_student_detail.withColumn('minimum', least('mathematics_score', 'science_score'))
df1.show()
So the resultant dataframe with row wise minimum calculated will be

Row wise maximum in pyspark : Method 1
greatest() function takes the column name as arguments and calculates the row wise maximum value.
### Row wise maximum in pyspark
from pyspark.sql.functions import col, greatest
df1=df_student_detail.select((greatest(col("mathematics_score"),col("science_score"))).alias("maximum"))
df1.show()

Row wise maximum in pyspark : Method 2
In method 2 two we will be appending the result to the dataframe by using greatest function. greatest() function takes the column name as arguments and calculates the row wise maximum value and the result is appended to the dataframe.
### Row wise maximum in pyspark
from pyspark.sql.functions import greatest
df1=df_student_detail.withColumn('maximum', greatest('mathematics_score', 'science_score'))
df1.show()
So the resultant dataframe with row wise maximum calculated will be

Other Related Topics:
- Simple random sampling and stratified sampling in pyspark – Sample(), SampleBy()
- Join in pyspark (Merge) inner , outer, right , left join in pyspark
- Get duplicate rows in pyspark
- Quantile rank, decile rank & n tile rank in pyspark – Rank by Group
- Populate row number in pyspark – Row number by Group
- Percentile Rank of the column in pyspark
- Mean of two or more columns in pyspark
- Sum of two or more columns in pyspark
- Row wise mean, sum, minimum and maximum in pyspark
- Rename column name in pyspark – Rename single and multiple column
- Typecast Integer to Decimal and Integer to float in Pyspark
- Get number of rows and number of columns of dataframe in pyspark
- Extract Top N rows in pyspark – First N rows
- Absolute value of column in Pyspark – abs() function
- Set Difference in Pyspark – Difference of two dataframe
- Union and union all of two dataframe in pyspark (row bind)
- Intersect of two dataframe in pyspark (two or more)
- Round up, Round down and Round off in pyspark – (Ceil & floor pyspark)
![]()
![]()
 and Max() Function in R")
")



