In Simple random sampling every individuals are randomly obtained and so the individuals are equally likely to be chosen. Simple Random sampling in pyspark is achieved by using sample() Function. Here we have given an example of simple random sampling with replacement in pyspark and simple random sampling in pyspark without replacement. In Stratified sampling every member of the population is grouped into homogeneous subgroups and representative of each group is chosen. Stratified sampling in pyspark is achieved by using sampleBy() Function. Lets look at an example of both simple random sampling and stratified sampling in pyspark.
- Simple random sampling in pyspark with example using sample() function
- Stratified sampling in pyspark with example
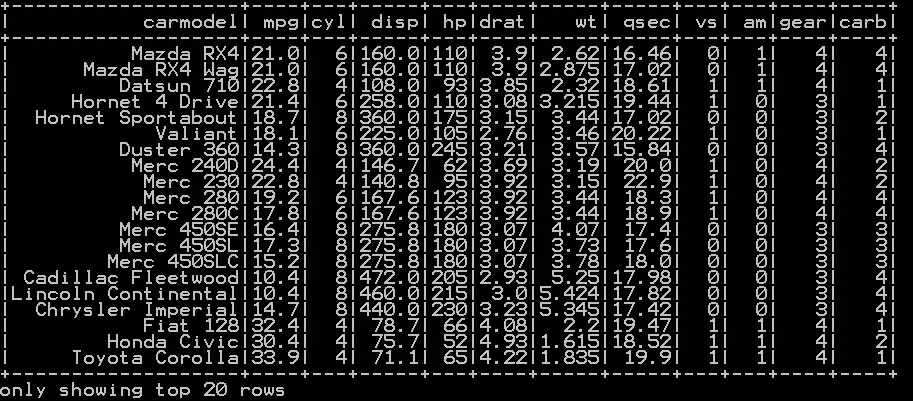
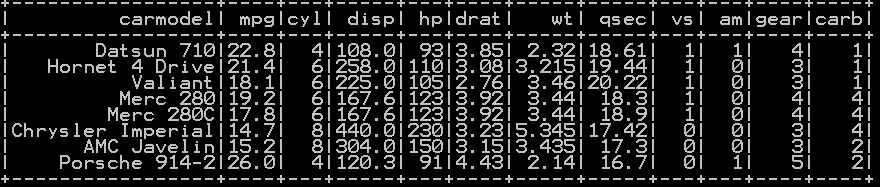
We will be using the dataframe df_cars
Simple random sampling in pyspark with example
In Simple random sampling every individuals are randomly obtained and so the individuals are equally likely to be chosen.
Simple random sampling without replacement in pyspark
Syntax:
Returns a sampled subset of Dataframe without replacement.
Note: fraction is not guaranteed to provide exactly the fraction specified in Dataframe
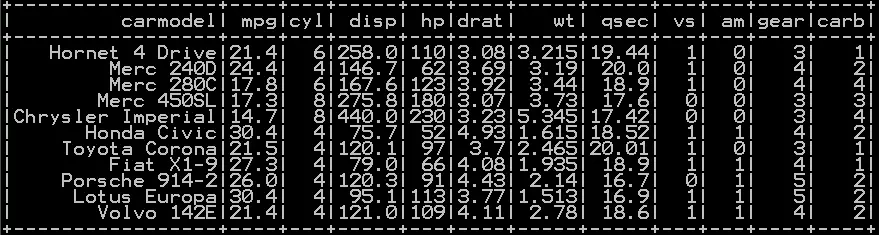
### Simple random sampling in pyspark df_cars_sample = df_cars.sample(False, 0.5, 42) df_cars_sample.show()
So the resultant sample without replacement will be
Simple random sampling with replacement
Syntax:
Returns a sampled subset of Dataframe with replacement.
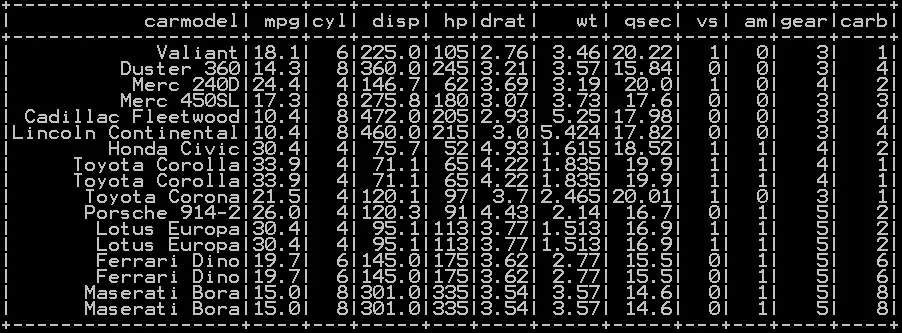
### Simple random sampling in pyspark with replacement df_cars_sample = df_cars.sample(True, 0.5, 42) df_cars_sample.show()
So the resultant sample with replacement will be
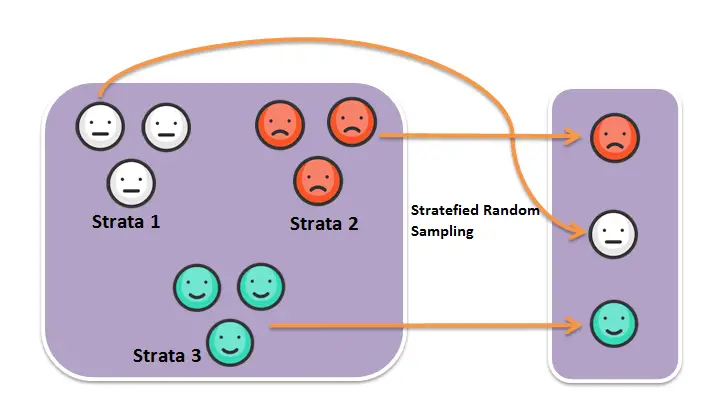
Stratified sampling in pyspark
In Stratified sampling every member of the population is grouped into homogeneous subgroups called strata and representative of each group (strata) is chosen.
Syntax:
### Stratified sampling in pyspark
from pyspark.sql.functions import col
sampled = df_cars.sampleBy("cyl", fractions={4: 0.2, 6: 0.4, 8: 0.2}, seed=0)
sampled.show()
From cyl column we have three subgroups or Strata – (4,6,8) which are chosen at fraction of 0.2, 0.4 and 0.2 respectively. We use sampleBy() function as shown above so the resultant sample will be
Other Related Topics:
- Join in pyspark (Merge) inner , outer, right , left join in pyspark
- Get duplicate rows in pyspark
- Quantile rank, decile rank & n tile rank in pyspark – Rank by Group
- Populate row number in pyspark – Row number by Group
- Percentile Rank of the column in pyspark
- Mean of two or more columns in pyspark
- Sum of two or more columns in pyspark
- Simple random sampling and stratified sampling in pyspark – Sample(), SampleBy()
- Row wise mean, sum, minimum and maximum in pyspark
- Rename column name in pyspark – Rename single and multiple column
- Typecast Integer to Decimal and Integer to float in Pyspark
- Get number of rows and number of columns of dataframe in pyspark
- Extract Top N rows in pyspark – First N rows
- Absolute value of column in Pyspark – abs() function
- Set Difference in Pyspark – Difference of two dataframe
- Union and union all of two dataframe in pyspark (row bind)
![]()
![]()
 Function in R")




