In order to read csv file in Pyspark and convert to dataframe, we import SQLContext. We will explain step by step how to read a csv file and convert them to dataframe in pyspark with an example.
We have used two methods to convert CSV to dataframe in Pyspark
Lets first import the necessary package
from pyspark.sql import SQLContext from pyspark.sql.types import * sqlContext = SQLContext(sc)
So we have imported SQLContext as shown above.
Method 1: Read csv and convert to dataframe in pyspark
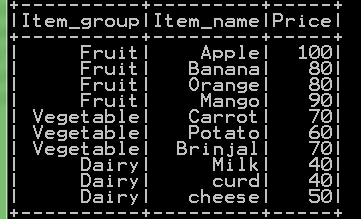
df_basket = sqlContext.read.format('com.databricks.spark.csv').options(header='true').load('C:/Users/Desktop/data/Basket.csv')
df_basket.show()
- We use sqlcontext to read csv file and convert to spark dataframe with header=’true’.
- Then we use load(‘your_path/file_name.csv’)
- The resultant dataframe is stored as df_basket
- df_basket.show() displays the top 20 rows of resultant dataframe
Method 2: Read csv and convert to dataframe in pyspark
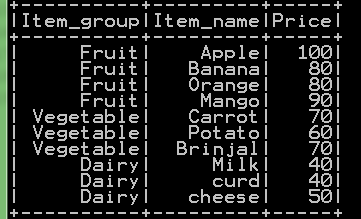
df_basket1= sqlContext.read.load('C:/Users/Desktop/data/Basket.csv',
format='com.databricks.spark.csv',
header='true',
inferSchema='true')
df_basket1.show()
Here we first give load(‘your_path/file_name.csv’) and then we pass arguments to format like header=’true’. So the resultant dataframe will be
![]()
![]()





