Groupby count in R can be accomplished by aggregate() or group_by() function of dplyr package. Groupby count of multiple column and single column in R is accomplished by multiple ways some among them are group_by() function of dplyr package in R and count the number of occurrences within a group using aggregate() function in R. Let’s see how to
- Groupby count of single column in R
- Groupby count of multiple columns
- Groupby count using aggregate() function
- Groupby count using group_by() function.
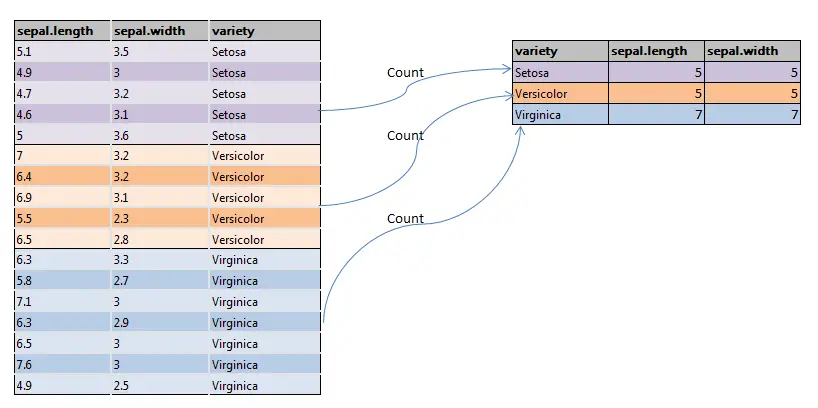
Groupby count and its functionality has been pictographically represented as shown below
First let’s create a dataframe
df1= data.frame(Name=c('James','Paul','Richards','Marico','Samantha','Ravi','Raghu','Richards','George','Ema','Samantha','Catherine'),
State=c('Alaska','California','Texas','North Carolina','California','Texas','Alaska','Texas','North Carolina','Alaska','California','Texas'),
Sales=c(14,24,31,12,13,7,9,31,18,16,18,14))
df1
df1 will be

Groupby using aggregate() syntax:
| X | an R object, Mostly a dataframe |
| by | a list of grouping elements, by which the subsets are grouped by |
| FUN | a function to compute the summary statistics |
| simplify | a logical indicating whether results should be simplified to a vector or matrix if possible |
| drop | a logical indicating whether to drop unused combinations of grouping values. |
Groupby count of single column in R:
Method 1:
Aggregate function along with parameter by – by which it is to be grouped and function length, is mentioned as shown below
# Groupby count of single column aggregate(df1$Sales, by=list(df1$State), FUN=length)
so the grouped dataframe will be

Method 2: groupby using dplyr
group_by() function takes “state” column as argument summarise() uses n() function to find count of sales.
library(dplyr) df1 %>% group_by(State) %>% summarise(count_sales = n())
so the grouped dataframe will be

Groupby count of multiple column in R:
Method 1:
aggregate() function which is grouped by “State” and “Name”, along with function length is mentioned as shown below
# Groupby count of multiple columns aggregate(df1$Sales, by=list(df1$State,df1$Name), FUN=length)
so the grouped dataframe will be

Method 2: groupby using dplyr
group_by() function along with n() is used to count the number of occurrences of the group in R. group_by() function takes “State” and “Name” column as argument and groups by these two columns and summarise() uses n() function to find count of a sales.
library(dplyr) df1 %>% group_by(State,Name) %>% summarise(count_sales = n())
so the grouped dataframe by “State” and “Name” column with aggregated count of sales will be

For further understanding of group by count() function in R using dplyr one can refer the dplyr documentation
Related Topics:
![]()
![]()


")

 in R using Dplyr – select () Function")