In pyspark we have one of the common errors which is like nameerror name ‘sqlcontext’ is not defined. The NameError: name ‘sqlcontext’ is not defined error typically occurs if you’re trying to use SQLContext without properly importing or initializing it.
The error will look like this
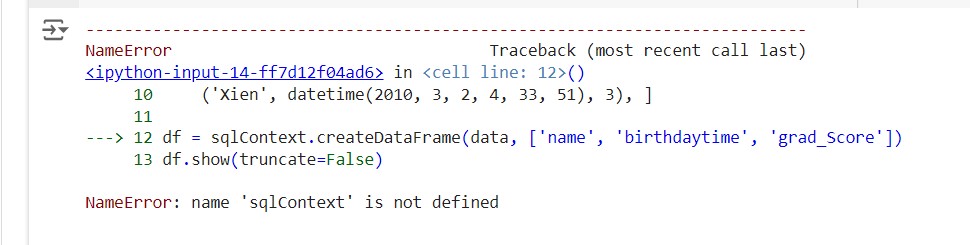
When one was creating dataframe such errors usually occurs
#### Error Case
import pyspark.sql.functions as F
from datetime import datetime
data = [
('George', datetime(2010, 3, 24, 3, 19, 58), 4),
('Andrew', datetime(2009, 12, 12, 17, 21, 30), 5),
('Micheal', datetime(2010, 11, 22, 13, 29, 40), 2),
('Maggie', datetime(2010, 2, 8, 3, 31, 23), 8),
('Ravi', datetime(2009, 1, 1, 4, 19, 47), 2),
('Xien', datetime(2010, 3, 2, 4, 33, 51), 3), ]
df = sqlContext.createDataFrame(data, ['name', 'birthdaytime', 'grad_Score'])
df.show(truncate=False)
on execution of the above code we will get the error : The NameError: name ‘sqlcontext’ is not defined as shown below.
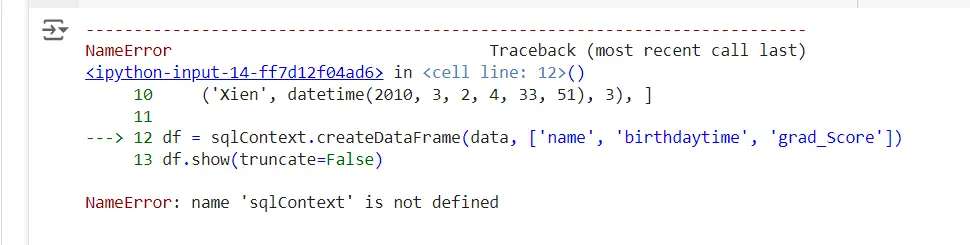
Solutions for the Error: nameerror name ‘sqlcontext’ is not defined in pyspark
Solution 1: using SQLContext
you generally do not need to use SQLContext directly. However, if you still want to use SQLContext, you can do so as follows:
import the SQLContext and define it before the create dataframe.
Fix part of the code :
from pyspark.sql import SQLContext sc=spark.sparkContext sqlContext = SQLContext(sc)
Complete code:
##Method 1: using SQLContext
import pyspark.sql.functions as F
from datetime import datetime
from pyspark.sql import SQLContext
sc=spark.sparkContext
sqlContext = SQLContext(sc)
from pyspark.sql import SparkSession
data = [
('George', datetime(2010, 3, 24, 3, 19, 58), 4),
('Andrew', datetime(2009, 12, 12, 17, 21, 30), 5),
('Micheal', datetime(2010, 11, 22, 13, 29, 40), 2),
('Maggie', datetime(2010, 2, 8, 3, 31, 23), 8),
('Ravi', datetime(2009, 1, 1, 4, 19, 47), 2),
('Xien', datetime(2010, 3, 2, 4, 33, 51), 3), ]
df = sqlContext.createDataFrame(data, ['name', 'birthdaytime', 'grad_Score'])
df.show(truncate=False)
The dataframe is created, so the output dataframe will be
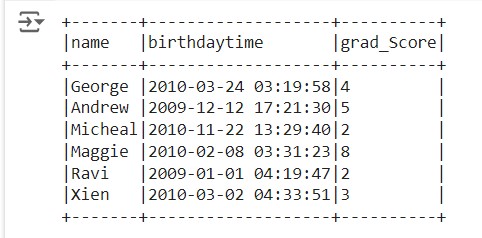
Solution 2:
In recent versions of PySpark, the SparkSession has become the main entry point, and you generally do not need to use SQLContext directly.
Solution 2: Using SparkSession
Here’s how to use SparkSession, which includes the functionality of SQLContext:
Fix part of the code :
from pyspark.sql import SparkSession
# Create a Spark session
spark = SparkSession.builder \
.appName("Example") \
.getOrCreate()
Complete code :
##Method 2: using Sparksession
###### create dataframe in pyspark
import pyspark.sql.functions as F
from datetime import datetime
from pyspark.sql import SparkSession
# Create a Spark session
spark = SparkSession.builder \
.appName("Example") \
.getOrCreate()
data = [
('George', datetime(2010, 3, 24, 3, 19, 58), 4),
('Andrew', datetime(2009, 12, 12, 17, 21, 30), 5),
('Micheal', datetime(2010, 11, 22, 13, 29, 40), 2),
('Maggie', datetime(2010, 2, 8, 3, 31, 23), 8),
('Ravi', datetime(2009, 1, 1, 4, 19, 47), 2),
('Xien', datetime(2010, 3, 2, 4, 33, 51), 3), ]
df = spark.createDataFrame(data, ['name', 'birthdaytime', 'grad_Score'])
df.show(truncate=False)
The dataframe is created, so the output dataframe will be
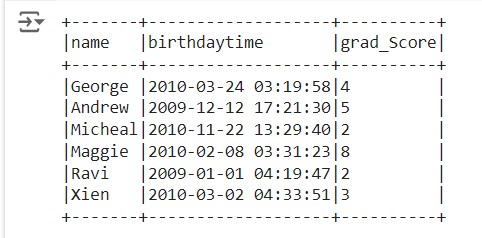

 function")
")
")

