Set difference of two dataframe in pandas is carried out in roundabout way using drop_duplicates and concat function. It will become clear when we explain it with an example.
Set difference of two dataframe in pandas Python:
Set difference of two dataframes in pandas can be achieved in roundabout way using drop_duplicates and concat function. Let’s see with an example. First let’s create two data frames.
import pandas as pd
import numpy as np
#Create a DataFrame
df1 = {
'Subject':['semester1','semester2','semester3','semester4','semester1',
'semester2','semester3'],
'Score':[62,47,55,74,31,77,85]}
df2 = {
'Subject':['semester1','semester2','semester3','semester4'],
'Score':[90,47,85,12]}
df1 = pd.DataFrame(df1,columns=['Subject','Score'])
df2 = pd.DataFrame(df2,columns=['Subject','Score'])
print(df1)
print(df2)
df1 will be
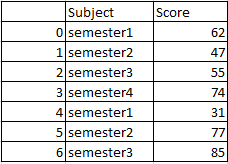
df2 will be
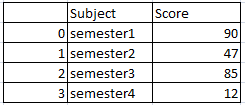
Set Difference of two dataframes in pandas python:
concat() function along with drop duplicates in pandas can be used to create the set difference of two dataframe as shown below.
Set difference of df2 over df1, something like df2.set_diff(df1) is shown below
set_diff_df = pd.concat([df2, df1, df1]).drop_duplicates(keep=False) print(set_diff_df)
so the set differenced dataframe will be (data in df2 but not in df1)
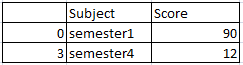
![]()
![]()

 data frames (inner, outer, left, right) in R")
 in pandas python")


 of a dataframe in python Pandas")