In this section we will learn how to find the duplicate rows of the dataframe in python pandas with duplicated() Function. Lets see with an example.
We will be marking the row as TRUE if it is duplicate and FALSE if it is not duplicate. Let’s try with an example.
# import pandas as pd
import numpy as np
#Create a DataFrame
d = {
'Name':['Alisa','Bobby','jodha','jack','raghu','Cathrine',
'Alisa','Bobby','kumar','Alisa','Alex','Cathrine'],
'Age':[26,24,23,22,23,24,26,24,22,23,24,24],
'Score':[85,63,55,74,31,77,85,63,42,62,89,77]}
df = pd.DataFrame(d,columns=['Name','Age','Score'])
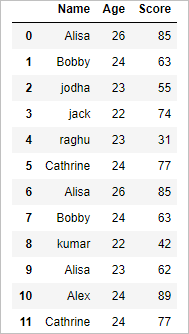
df
so the resultant dataframe will be
Find the duplicate row in pandas:
duplicated() function is used for find the duplicate rows of the dataframe in python pandas
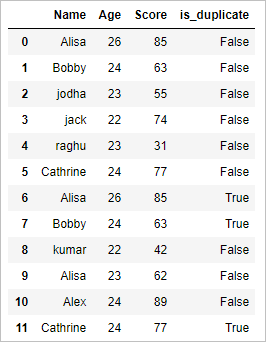
df["is_duplicate"]= df.duplicated() df
The above code finds whether the row is duplicate and tags TRUE if it is duplicate and tags FALSE if it is not duplicate. And assigns it to the column named “is_duplicate” of the dataframe df.
So the resultant dataframe will be,
![]()
![]()
 function")


 of a dataframe in python Pandas")

