Distinct function in R is used to remove duplicate rows in R using Dplyr package. Dplyr package in R is provided with distinct() function which eliminate duplicates rows with single variable or with multiple variable. There are other methods to drop duplicate rows in R one method is duplicated() which identifies and removes duplicate in R. The other method is unique() which identifies the unique values.
we will looking at example on How to
- Get distinct Rows of the dataframe in R using distinct() function.
- Remove duplicate rows based on two or more variables/columns in R
- Drop duplicates of the dataframe using duplicated() function in R
- Get unique rows (remove duplicate rows) of the dataframe in R using unique() function.
Create Dataframe
We will be using the following dataframe to depict the above functions. Lets first create the dataframe.
# simple Data frame creation
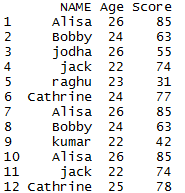
mydata = data.frame (NAME =c ('Alisa','Bobby','jodha','jack','raghu','Cathrine',
'Alisa','Bobby','kumar','Alisa','jack','Cathrine'),
Age = c (26,24,26,22,23,24,26,24,22,26,22,25),
Score =c(85,63,55,74,31,77,85,63,42,85,74,78))
mydata
so the resultant data frame will be
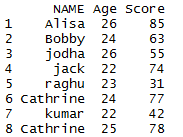
distinct() Function in Dplyr – Remove duplicate rows of a dataframe in R:
library(dplyr) # Remove duplicate rows of the dataframe distinct(mydata)
OR
library(dplyr) mydata %>% distinct()
In this dataset, all the duplicate rows are eliminated so it returns the unique rows in mydata.
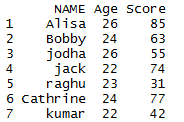
Remove Duplicate Rows based on a variable
We will be removing duplicate rows using a particular variable.
library(dplyr) # Remove duplicate rows of the dataframe using NAME variable distinct(mydata,NAME, .keep_all= TRUE)
OR
library(dplyr) mydata %>% distinct(NAME, .keep_all= TRUE)
The .keep_all function is used to retain all other variables in the output data frame. So the output dataframe will be
Remove Duplicate Rows based on multiple variables
We will be removing duplicate rows using Multiple variables in the below example.
library(dplyr) # Remove duplicate rows of the dataframe using NAME and Age variables distinct(mydata, NAME,Age, .keep_all= TRUE)
OR
library(dplyr) mydata %>% distinct(NAME,Age, .keep_all= TRUE)
The .keep_all function is used to retain all other variables in the output data frame. So the resultant dataframe will be
DROP Duplicates in R using unique() function in R
When we apply unique function to the above data frame
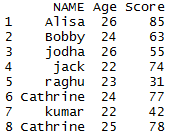
## Apply unique function for data frame in R unique(mydata)
Duplicate entries in the data frame are eliminated and the final output will be
unique rows of the dataframe by keeping last occurrences
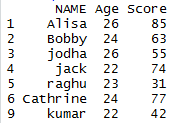
unique() function along with the argument fromLast =T indicates keeping the last occurrence in the process of identifying unique values
## unique value of dataframe in R by keeping last occurrences unique(mydata, fromLast=T)
unique values of a dataframe by keeping last occurrences will be
unique value of the columns in the dataframe
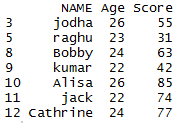
unique() function takes up the column name as argument and results in identifying unique value of the particular column as shown below
## unique value of the column in R dataframe unique(mydata$NAME)
so the unique values of the name column will be
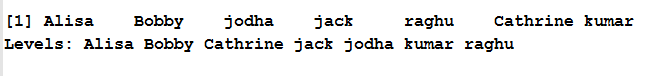
Remove Duplicates based on a column using duplicated() function
duplicated() function along with [!] takes up the column name as argument and results in identifying unique value of the particular column as shown below
## unique value of the column in R dataframe mydata[!duplicated(mydata$NAME), ]
so the dataframe with unique values of the NAME column will be
For Further understanding on how to drop duplicate rows in R using Dplyr one can refer dplyr documentation
Other Related Topics :
![]()
![]()

 in R using Dplyr – select () Function")


