In this section we will learn how to drop or delete the row in python pandas by index, delete row by condition in python pandas and drop rows by position. Dropping a row in pandas is achieved by using .drop() function. Lets see example of each.
- Delete or Drop rows with condition in python pandas using drop() function.
- Drop rows by index / position in pandas.
- Remove or Drop NA rows or missing rows in pandas python.
- Remove or Drop Rows with Duplicate values in pandas.
- Drop or remove rows based on multiple conditions pandas
Syntax of drop() function in pandas :
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=’raise’)
- labels: String or list of strings referring row.
- axis: int or string value, 0 ‘index’ for Rows and 1 ‘columns’ for Columns.
- index or columns: Single label or list. index or columns are an alternative to axis and cannot be used together.
- level: Used to specify level, in case data frame is having multiple level index.
- inplace: Makes changes in original Data Frame if True.
- errors: Ignores error if any value from the list doesn’t exists and drops rest of the values when errors = ‘ignore’.
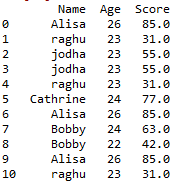
Create Dataframe:
import pandas as pd
import numpy as np
#Create a DataFrame
import pandas as pd
import numpy as np
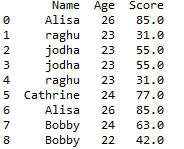
d = { 'Name':['Alisa','raghu','jodha','jodha','raghu','Cathrine', 'Alisa','Bobby','Bobby','Alisa','raghu','Cathrine'],
'Age':[26,23,23,23,23,24,26,24,22,26,23,24],
'Score':[85,31,55,55,31,77,85,63,42,85,31,np.nan]}
df = pd.DataFrame(d,columns=['Name','Age','Score'])
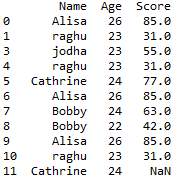
df
the dataframe will be
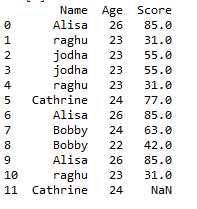
Simply drop a row or observation:
Dropping the second and third row of a dataframe is achieved as follows
# Drop an observation or row df.drop([1,2])
The above code will drop the second and third row.
0 – represents 1st row
1- represnts 2nd row and so on. So the resultant dataframe will be
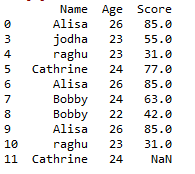
Drop a row or observation by condition:
we can drop a row when it satisfies a specific condition
# Drop a row by condition df[df.Name != 'Alisa']
The above code takes up all the names except Alisa, thereby dropping the row with name ‘Alisa’. So the resultant dataframe will be
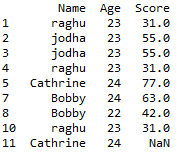
Drop a row or observation by index:
We can drop a row by index as shown below
# Drop a row by index df.drop(df.index[2])
The above code drops the row with index number 2. So the resultant dataframe will be
Drop the row by position:
Now let’s drop the bottom 3 rows of a dataframe as shown below
# Drop bottom 3 rows df[:-3]
The above code selects all the rows except bottom 3 rows, there by dropping bottom 3 rows, so the resultant dataframe will be
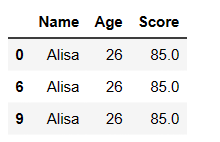
Drop Rows with multiple conditions in pandas:
Now lets drop all the rows where age is between 20 and 25 .
indexAge = df[ (df['Age'] >= 20) & (df['Age'] <= 25) ].index df.drop(indexAge , inplace=True) df
Output:
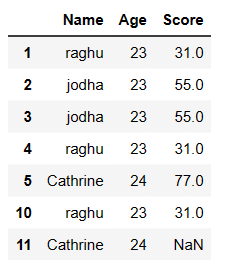
Drop Rows with multiple conditions in pandas based on multiple columns:
Remove rows where Name is Bobby or Catherine or any person with Age >=26. these conditions are specified below
indexAge = df[ (df['Name'].isin(['Bobby', 'Catherine']) | (df['Age'] >= 26)) ].index df.drop(indexAge , inplace=True) df
Output:
Drop Duplicate rows of the dataframe in pandas
now lets simply drop the duplicate rows in pandas as shown below
# drop duplicate rows df.drop_duplicates()
In the above example first occurrence of the duplicate row is kept and subsequent duplicate occurrence will be deleted, so the output will be
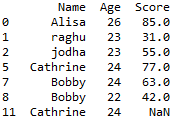
For further detail on drop duplicates one can refer our page on Drop duplicate rows in pandas python drop_duplicates()
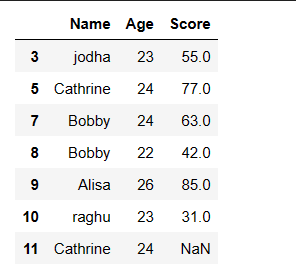
Drop or Remove Duplicate rows by keeping first and last occurrence:
# Remove Duplicate rows by keeping last occurence df.drop_duplicates(keep='last')
Output:
# Remove Duplicate rows by keeping First occurence df.drop_duplicates(keep='first')
Output:
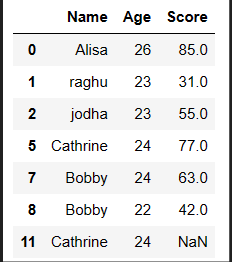
Drop rows with NA values in pandas python
Remove or Drop the rows even with single NaN or single missing values.
df.dropna()
so the resultant table on which rows with NA values dropped will be
Outputs:
For further detail on drop rows with NA values one can refer our page
Other related topics :
- Find the duplicate rows in pandas
- Drop or delete column in pandas
- Get maximum value of column in pandas
- Get minimum value of column in pandas
- select row with maximum and minimum value in pandas
- Get unique values of dataframe in Pandas
for documentation on drop() function kindly refer here.
![]()
![]()





