In order to get duplicate rows in pyspark we use round about method. First we do groupby count of all the columns and then we filter the rows with count greater than 1. Thereby we keep or get duplicate rows in pyspark. We can also assign a flag which indicates the duplicate records which is nothing but flagging duplicate row or getting indices of the duplicate rows in pyspark there by check if duplicate row is present
- Get Duplicate rows in pyspark using groupby count function – Keep or extract duplicate records.
- Flag or check the duplicate rows in pyspark – check whether a row is a duplicate row or not.
We will be using dataframe df_basket1

Get Duplicate rows in pyspark : Keep Duplicate rows in pyspark:
In order to keep only duplicate rows in pyspark we will be using groupby function along with count() function.
### Get Duplicate rows in pyspark
df1=df_basket1.groupBy("Item_group","Item_name","price").count().filter("count > 1")
df1.drop('count').show()
- First we do groupby count of all the columns i.e. “Item_group”,”Item_name”,”price”
- Secondly we filter the rows with count greater than 1.
So the resultant duplicate rows are

Flag or Check Duplicate rows in pyspark:
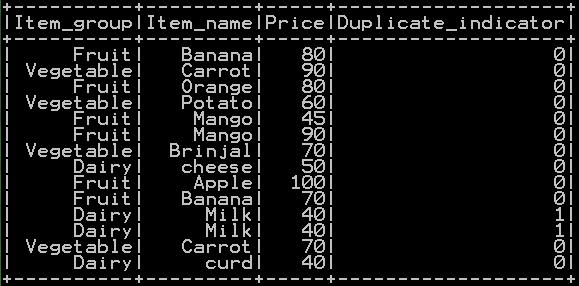
In order to check whether the row is duplicate or not we will be generating the flag “Duplicate_Indicator” with 1 indicates the row is duplicate and 0 indicate the row is not duplicate. This is accomplished by grouping dataframe by all the columns and taking the count. if count more than 1 the flag is assigned as 1 else 0 as shown below.
### flag or check Duplicate rows in pyspark
import pyspark.sql.functions as f
df_basket1.join(
df_basket1.groupBy(df_basket1.columns).agg((f.count("*")>1).cast("int").alias("Duplicate_indicator")),
on=df_basket1.columns,
how="inner"
).show()
- so the resultant dataframe with duplicate rows flagged as 1 and non duplicates rows flagged as 0 will be
Other Related Topics:
- Drop rows in pyspark – drop rows with condition
- Distinct value of a column in pyspark
- Distinct value of dataframe in pyspark – drop duplicates
- Count of Missing (NaN,Na) and null values in Pyspark
- Mean, Variance and standard deviation of column in Pyspark
- Maximum or Minimum value of column in Pyspark
- Raised to power of column in pyspark – square, cube , square root and cube root in pyspark
- Drop column in pyspark – drop single & multiple columns
- Subset or Filter data with multiple conditions in pyspark
- Frequency table or cross table in pyspark – 2 way cross table
- Groupby functions in pyspark (Aggregate functions) – Groupby count, Groupby sum, Groupby mean, Groupby min and Groupby max
- Descriptive statistics or Summary Statistics of dataframe in pyspark
- Rearrange or reorder column in pyspark
![]()
![]()
")


")
")
